

Docker Model Runner: Guia de Configuração do Tamanho do Contexto
Configure tamanhos de contexto no Docker Model Runner com soluções alternativas
A configuração de tamanhos de contexto no Docker Model Runner é mais complexa do que deveria.
Configure tamanhos de contexto no Docker Model Runner com soluções alternativas
A configuração de tamanhos de contexto no Docker Model Runner é mais complexa do que deveria.

Ative a aceleração por GPU para o Docker Model Runner com suporte NVIDIA CUDA.
Docker Model Runner é a ferramenta oficial da Docker para executar modelos de IA localmente, mas habilitar a aceleração de GPU da NVidia no Docker Model Runner requer configuração específica.
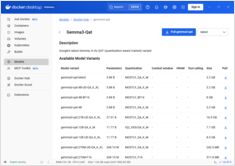
Referência rápida para comandos do Docker Model Runner
Docker Model Runner (DMR) é a solução oficial do Docker para executar modelos de IA localmente, introduzida em abril de 2025. Esta lista de comandos essenciais fornece uma referência rápida para todos os comandos, configurações e melhores práticas.
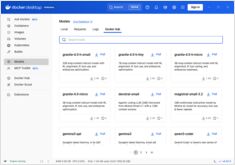
Compare o Docker Model Runner e o Ollama para LLM locais.
Execução local de grandes modelos de linguagem (LLMs) tornou-se cada vez mais popular devido à privacidade, controle de custos e capacidades offline. O cenário mudou significativamente em abril de 2025, quando a Docker introduziu o Docker Model Runner (DMR), sua solução oficial para implantação de modelos de IA.

Integre o Ollama com Go: guia do SDK, exemplos e melhores práticas para produção.
Este guia oferece uma visão abrangente dos SDKs Go para Ollama e compara seus conjuntos de funcionalidades.

+ Exemplos Específicos Utilizando LLMs de Raciocínio
Neste post, exploraremos duas maneiras de conectar sua aplicação Python ao Ollama: 1. Via API REST HTTP; 2. Via a biblioteca oficial Python do Ollama.

Minha visão sobre o estado atual do desenvolvimento do Ollama
A Ollama tornou-se rapidamente uma das ferramentas mais populares para executar LLMs localmente.
Sua CLI simples e gestão de modelos simplificada tornaram-na uma opção preferencial para desenvolvedores que desejam trabalhar com modelos de IA fora da nuvem.
Visão geral rápida das principais interfaces de usuário para Ollama em 2025
O Ollama hospedado localmente permite executar modelos de linguagem grandes na sua própria máquina, mas usá-lo via linha de comando não é amigável. Aqui estão vários projetos de código aberto que oferecem interfaces estilo ChatGPT que se conectam a uma instância local do Ollama.

Qwen3 8B, 14B e 30B, Devstral 24B e Mistral Small 24B
Neste teste, estou comparando como diferentes LLMs hospedados no Ollama traduzem páginas do Hugo de inglês para alemão.

Lista curta de provedores de LLM
Usar LLMs não é muito caro; pode ser que não haja necessidade de comprar uma nova GPU incrível. Abaixo está uma lista de provedores de LLM na nuvem com os LLMs que hospedam.

Comparando dois modelos deepseek-r1 com dois modelos base
A primeira geração de modelos de raciocínio da DeepSeek com desempenho comparável ao OpenAI-o1, incluindo seis modelos densos destilados do DeepSeek-R1 com base em Llama e Qwen.

Lista de comandos Ollama atualizada — ls, ps, run, serve, etc.
Este resumo de comandos da CLI do Ollama foca nos comandos que você usa todos os dias (ollama ls, ollama serve, ollama run, ollama ps, gerenciamento de modelos e fluxos de trabalho comuns), com exemplos que você pode copiar e colar.

Comparando dois motores de busca de IA auto-hospedados
Comida incrível é um prazer também para os seus olhos. Mas, neste post, compararemos dois sistemas de busca baseados em IA, Farfalle e Perplexica.
Executando um serviço estilo Copilot localmente? Fácil!
Isso é muito emocionante! Em vez de chamar o Copilot ou o Perplexity.ai e contar a todos o que você busca, agora você pode hospedar um serviço similar no seu próprio PC ou laptop!

Os arquivos de modelos LLM do Ollama ocupam muito espaço.
Após instalar o Ollama, é melhor reconfigurar o Ollama para armazená-los em um novo local imediatamente. Assim, após baixar um novo modelo, ele não será baixado para o local antigo.