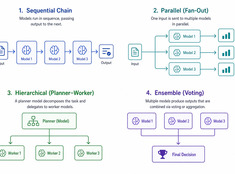
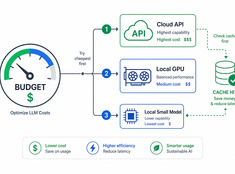
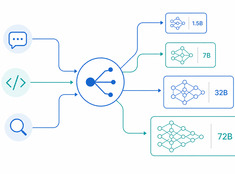
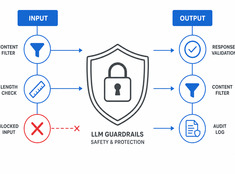
Цифровые сады: выращивайте знания, а не просто публикуйте их
Публикуйте знания, которые развиваются, а не просто посты.
Доминирующая модель публикации знаний в Интернете практически не изменилась с начала 2000-х годов: написать что-то, отредактировать, опубликовать и двигаться дальше.