MTP и стандартное декодирование на RTX 4080 — реальные бенчмарки
Я протестировал производительность спекулятивного декодирования (Multi-Token Prediction, MTP) в моделях Qwen 3.6 27B и 35B на видеокарте RTX 4080 с 16 ГБ видеопамяти (VRAM).
скорость обработки токенов llama.cpp на 16 ГБ VRAM (таблицы).
В этом посте я сравниваю скорость работы нескольких больших языковых моделей (LLM) на GPU с 16 ГБ видеопамяти (VRAM) и выбираю лучшую для самостоятельного хостинга.
Управляйте данными и моделями с помощью развернутых локально LLM
Хостинг больших языковых моделей (LLM) на собственных серверах обеспечивает контроль над данными, моделями и процессом инференса — это практический путь к суверенному искусственному интеллекту для команд, предприятий и целых стран.
Запуск больших языковых моделей локально обеспечивает конфиденциальность, возможность работы автономно и нулевые затраты на API.
Это тестирование показывает, чего именно можно ожидать от 14 популярных
LLM в Ollama на RTX 4080.
Сегодня мы рассматриваем топовые потребительские графические процессоры и модули оперативной памяти. Конкретно я смотрю на цены на RTX-5080 и RTX-5090, а также на 32ГБ (2x16ГБ) DDR5 6000.
Актуальные цены в австралийских долларах от местных розничных продавцов уже доступны.
Компьютер
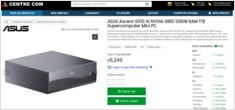
NVIDIA DGX Spark
(GB10 Grace Blackwell)
поступил в продажу в Австралии
у крупных розничных продавцов компьютеров с наличием на местных складах.
Если вы следите за
мировым ценообразованием и доступностью DGX Spark,
то вам будет интересно узнать, что в Австралии цены варьируются от 6 249 до 7 999 австралийских долларов в зависимости от конфигурации накопителей и конкретного продавца.
После автоматической установки нового ядра, Ubuntu 24.04 потеряла сетевое подключение по Ethernet. Эта раздражающая проблема произошла со мной во второй раз, поэтому я документирую решение здесь, чтобы помочь другим, столкнувшимся с той же проблемой.
Развертывание корпоративного ИИ на бюджетном оборудовании с использованием открытых моделей.
Демократизация искусственного интеллекта уже здесь.
С появлением открытых LLM, таких как Llama, Mistral и Qwen, которые теперь не уступают проприетарным моделям, команды могут создавать мощную инфраструктуру ИИ на потребительском оборудовании — значительно сокращая расходы при сохранении полного контроля над конфиденциальностью данных и развертыванием.