
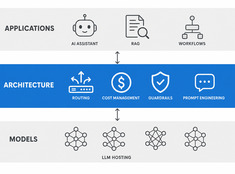
Архитектура LLM: проектирование систем для ИИ в продакшене
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
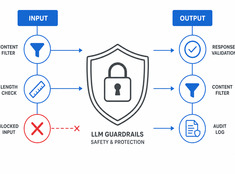
«Контролируйте риски, а не только модель»
Языковые модели (LLM) непредсказуемы. Они галлюцинируют, утекают данные, генерируют вредоносный контент или отказываются выполнять законные запросы. Ограничительные механизмы (guardrails) сужают поведение модели, не снижая при этом её возможностей.
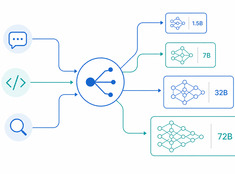
Правильная модель для правильной задачи.
Запуск модели с 70 миллиардами параметров для суммаризации электронного письма из 200 слов — это расточительство. Запуск модели с 3 миллиардами параметров для ревью продакшн-кода — это безрассудство. Большинство систем находятся где-то посередине, и именно здесь в игру вступает роутинг моделей (маршрутизация запросов).
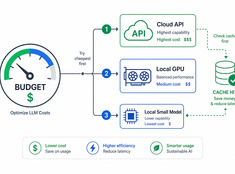
Тратьте токены там, где они действительно важны.
Стоимость использования больших языковых моделей (LLM) растет линейно в зависимости от объема запросов. Система, обрабатывающая 10 000 запросов в день по цене $0,01 за запрос, обходится в $100 ежедневно — это $365 в год. В корпоративном масштабе эта сумма превышает $10 000.
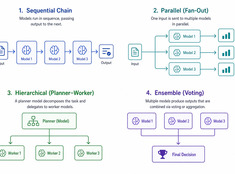
Выберите самый простой работающий паттерн.
Системы с одной моделью просты. Системы с несколькими моделями мощны. Сложность заключается не в выборе моделей, а в проектировании архитектуры, которая ими управляет.

Рабочая, структурированная и память извлечения для ассистентов.
Память превращает ассистентов из реактивных в персистентные системы, но именно здесь многие системы тихо деградируют. Исследования показывают, что разделение на кратковременную и долгосрочную память больше не достаточно для современной памяти агентов; OpenAI и SDK LangGraph указывают на более простую архитектуру — рабочую память, персистентное состояние и извлечение данных.

«Как на самом деле создаются серьёзные ассистенты»
Система AI-ассистента в продакшене — это не просто «LLM с промптом». Это система, которая принимает намерения пользователя, сохраняет состояние, решает, когда нужно извлечь данные или выполнить действие, и предоставляет достаточно деталей во время выполнения для отладки сбоев.

ИИ меняет управление знаниями, а не его цель.
Искусственный интеллект не заменяет управление знаниями; он меняет его форму как для отдельных лиц, так и для команд.
Звёзды, токены, загрузки — кто на самом деле выигрывает?
Фреймворки для ИИ-агентов с открытым исходным кодом стремительно набирают популярность на GitHub. Два проекта, являющихся основой экосистемы самохостинговых ИИ-систем — OpenClaw и Hermes Agent — настолько опередили остальных, что вся остальная отрасль борется за отдаленное третье место.

MTP и стандартное декодирование на RTX 4080 — реальные бенчмарки
Я протестировал производительность спекулятивного декодирования (Multi-Token Prediction, MTP) в моделях Qwen 3.6 27B и 35B на видеокарте RTX 4080 с 16 ГБ видеопамяти (VRAM).

Свободная VRAM без остановки llama-server
Режим маршрутизации llama.cpp — одно из самых полезных изменений в llama-server за последние годы. Наконец-то локальным операторам LLM предоставляется опыт управления моделями, близкий к тому, к которому пользователи привыкли в Ollama, при этом сохраняются высокая производительность и низкоуровневый контроль, которые делают llama.cpp стоящими того, чтобы использовать их в первую очередь.

Скомпилированные знания для ИИ-систем
Основная идея проста: скомпилированные знания более пригодны для повторного использования, чем извлеченные фрагменты. RAG стал стандартным ответом на простой вопрос — как предоставить LLM доступ к внешним знаниям?

«Карта современных систем знаний»
PKM, RAG, вики, системы памяти ИИ и теперь практические рабочие процессы с помощью ИИ часто обсуждаются так, будто они решают одну и ту же проблему. Это не так. Все они имеют дело с знаниями, но работают на разных уровнях:

Перестаньте полагаться на интуицию. Валидируйте контракты.
Большинство руководств по «структурированному выводу» (structured output) для больших языковых моделей (LLM) не обладают должной серьезностью. Они учат вас вежливо просить модель выдавать JSON и затем надеяться, что она поступит правильно. Это не валидация. Это оптимизм, обернутый в фигурные скобки.

Справочное руководство по настройке агентов LLM
Эта страница представляет собой практическое руководство по настройке агентов на базе LLM (температура, top_p, top_k, штрафы и их взаимодействие в многоступенчатых рабочих процессах с интенсивным использованием инструментов).

Общайтесь с Hermes со своего телефона
Вы уже общаетесь с агентом Hermes через телефон, используя текстовые сообщения. Теперь вы хотите говорить с ним напрямую и получать ответы голосом. Как правило, это правильное решение, особенно если вы уже используете Hermes как постоянно работающего автономного ассистента. Ввод длинных подсказок на маленьком экране медленный и подвержен ошибкам.