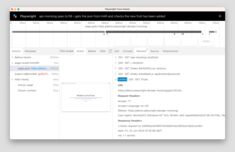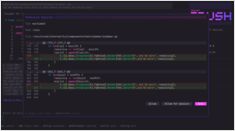
Шпаргалка по Hermes Agent CLI — команды, флаги и сокращения с косой чертой
Команды Shell и TUI для самостоятельного развертывания агента Hermes.
Hermes Agent от Nous Research — это модельно-независимый ассистент, использующий инструменты, который вы можете запускать локально или на VPS.