

Comparação da qualidade da tradução de páginas do Hugo - LLMs no Ollama
Qwen3 8B, 14B e 30B, Devstral 24B e Mistral Small 24B
Neste teste, estou comparando como diferentes LLMs hospedados no Ollama traduzem páginas do Hugo de inglês para alemão.
Qwen3 8B, 14B e 30B, Devstral 24B e Mistral Small 24B
Neste teste, estou comparando como diferentes LLMs hospedados no Ollama traduzem páginas do Hugo de inglês para alemão.

Implementando RAG? Aqui estão alguns snippets de código em Golang.
Este pequeno Exemplo de código Go para reranking que chama o Ollama para gerar embeddings é usado para a consulta e para cada documento candidato, ordenando em ordem decrescente por similaridade cosseno.

Novos e incríveis LLMs disponíveis no Ollama
Os modelos Qwen3 de Embedding e Reranker são os lançamentos mais recentes da família Qwen, projetados especificamente para tarefas avançadas de incorporação (embedding), recuperação e reclassificação de texto.

Pensando em instalar uma segunda GPU para LLMs?
Como as Pistas PCIe Afetam o Desempenho de LLM? Depende da tarefa. Para treinamento e inferência multi-GPU, a queda de desempenho é significativa.

LLM para extrair texto de HTML...
Na biblioteca de modelos do Ollama, existem modelos capazes de converter conteúdo HTML para Markdown, o que é útil para tarefas de conversão de conteúdo.

Cursor AI vs GitHub Copilot vs Cline AI vs...
Aqui, listarei algumas ferramentas de codificação assistidas por IA e Assistentes de Codificação com IA, bem como seus pontos positivos.

Ollama em CPUs Intel: núcleos eficientes versus núcleos de desempenho
Tenho uma teoria para testar: se utilizar todos os núcleos de uma CPU Intel aumentaria a velocidade dos LLMs? Isso tem me incomodado: o novo modelo gemma3 de 27 bilhões (gemma3:27b, 17GB no Ollama) não cabe nos 16GB de VRAM da minha GPU e está rodando parcialmente na CPU.

Compreenda a concorrência e o enfileiramento no Ollama, e como ajustar OLLAMA_NUM_PARALLEL para solicitações paralelas estáveis.
Este guia explica como o Ollama lida com solicitações paralelas (concorrência, filas e limites de recursos) e como ajustá-lo usando a variável de ambiente OLLAMA_NUM_PARALLEL (e outros parâmetros relacionados).

Comparando dois modelos deepseek-r1 com dois modelos base
A primeira geração de modelos de raciocínio da DeepSeek com desempenho comparável ao OpenAI-o1, incluindo seis modelos densos destilados do DeepSeek-R1 com base em Llama e Qwen.

Lista de comandos Ollama atualizada — ls, ps, run, serve, etc.
Este resumo de comandos da CLI do Ollama foca nos comandos que você usa todos os dias (ollama ls, ollama serve, ollama run, ollama ps, gerenciamento de modelos e fluxos de trabalho comuns), com exemplos que você pode copiar e colar.

Próxima rodada de testes de LLM
Não foi muito tempo atrás que foi lançado. Vamos dar uma olhada e testar como o Mistral Small se compara a outros LLMs.

Um código Python para o reranking de RAG

Comparando dois motores de busca de IA auto-hospedados
Comida incrível é um prazer também para os seus olhos. Mas, neste post, compararemos dois sistemas de busca baseados em IA, Farfalle e Perplexica.
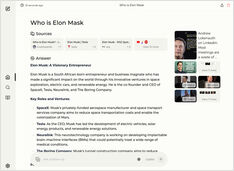
Executando um serviço estilo Copilot localmente? Fácil!
Isso é muito emocionante! Em vez de chamar o Copilot ou o Perplexity.ai e contar a todos o que você busca, agora você pode hospedar um serviço similar no seu próprio PC ou laptop!

Teste de detecção de falácias lógicas
Recentemente, vimos o lançamento de vários novos LLMs. Tempos emocionantes. Vamos testar e ver como eles se comportam na detecção de falácias lógicas.

Exige alguma experimentação, mas
Ainda assim, existem algumas abordagens comuns sobre como escrever bons prompts para que os LLMs não fiquem confusos ao tentar entender o que se espera deles.