

A Ascensão e Queda do OpenClaw — Cronologia e as Verdadeiras Razões por Trás do Colapso
OpenClaw surgiu rapidamente. Depois desapareceu ainda mais depressa.
O OpenClaw não fracassou como produto. Ele perdeu seu combustível.
OpenClaw surgiu rapidamente. Depois desapareceu ainda mais depressa.
O OpenClaw não fracassou como produto. Ele perdeu seu combustível.

Servir e trocar LLMs sem reinícios.
Por muito tempo, o llama.cpp teve uma limitação gritante:
era possível servir apenas um modelo por processo, e a troca exigia uma reinicialização.

Crie habilidades do Claude que resistam ao trabalho real.
A maioria das equipes usa as Skills do Claude de uma das duas maneiras erradas. Ou transformam o SKILL.md em um depósito de tudo, ou nunca deixam de usar prompts gigantes copiados e colados.

Configurações do Hermes com perfil em primeiro lugar para cargas de trabalho sérias
O assistente de IA Hermes, documentado oficialmente como Hermes Agent, não se posiciona como um simples wrapper de chat.

As habilidades que valem a pena manter e as que devem ser ignoradas
O OpenClaw possui dois tipos de extensões, e é fácil confundi-los.
Plugins estendem o tempo de execução. Skills (habilidades) estendem o comportamento do agente.

Plugins primeiro. Nomenclatura de habilidades em resumo.
Este artigo trata dos plugins do OpenClaw — pacotes nativos de gateway que adicionam canais, provedores de modelos, ferramentas, voz, memória, mídia, pesquisa web e outras superfícies de tempo de execução.

Como os sistemas reais do OpenClaw são realmente estruturados
OpenClaw parece simples em demonstrações. Em produção, ele se torna um sistema.

As assinaturas do Claude já não alimentam agentes
A brecha silenciosa que impulsionou uma onda de experimentação com agentes agora está fechada.

Busca de IA autohospedada com LLMs locais
Vane é uma das entradas mais pragmáticas no espaço de “busca de IA com citações”: um motor de respostas auto-hospedado que combina recuperação da web em tempo real com LLMs locais ou na nuvem, mantendo toda a pilha sob seu controle.

Codificação agentiva, agora com backends de modelos locais.
O Claude Code não é um autocompletar com melhor marketing. É uma ferramenta de codificação agêntica: lê sua base de código, edita arquivos, executa comandos e integra-se às suas ferramentas de desenvolvimento.

Instalação e início rápido do Hermes Agent para desenvolvedores
O Hermes Agent é um assistente de IA auto-hospedado e agnóstico em relação ao modelo, que é executado em uma máquina local ou em um VPS de baixo custo, opera por meio de interfaces de terminal e mensagens e melhora com o tempo, transformando tarefas repetidas em habilidades reutilizáveis.

Instale o TGI, desenvolva rapidamente e depure ainda mais rápido.
A Inferência de Geração de Texto (TGI) tem uma energia muito específica. Não é o mais novo na rua da inferência, mas é aquele que já aprendeu como a produção quebra -

Velocidade de tokens do llama.cpp em 16 GB de VRAM (tabelas).
Aqui estou comparando a velocidade de vários LLMs rodando em GPU com 16GB de VRAM e escolhendo o melhor para auto-hospedagem.

Servidor Ollama com prioridade na composição, suporte a GPU e persistência.
Ollama funciona muito bem em metal nu. Torna-se ainda mais interessante quando tratado como um serviço: um endpoint estável, versões fixas, armazenamento persistente e uma GPU que está disponível ou não.
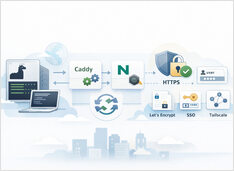
HTTPS Ollama sem interromper as respostas em streaming.
Executar o Ollama atrás de um proxy reverso é a maneira mais simples de obter HTTPS, controle de acesso opcional e comportamento de streaming previsível.

Execute modelos abertos com rapidez usando o SGLang.
O SGLang é um framework de serviço de alto desempenho para grandes modelos de linguagem e modelos multimodais, construído para fornecer inferência de baixa latência e alto throughput, desde uma única GPU até clusters distribuídos.