
LLM-ограничители на практике: что действительно работает
«Контролируйте риски, а не только модель»
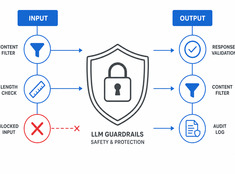
Языковые модели (LLM) непредсказуемы. Они галлюцинируют, утекают данные, генерируют вредоносный контент или отказываются выполнять законные запросы. Ограничительные механизмы (guardrails) сужают поведение модели, не снижая при этом её возможностей.