Шпаргалка по Docker Model Runner: команды и примеры
Быстрая справка по командам Docker Model Runner
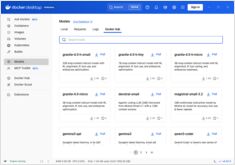
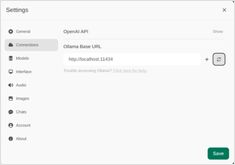
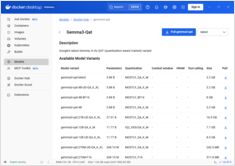
Docker Model Runner (DMR) — это официальное решение Docker для запуска моделей ИИ локально, представленное в апреле 2025 года. Этот справочник предоставляет быстрый доступ ко всем основным командам, настройкам и лучшим практикам.