Метрики, дашборды и оповещения для производственных систем — Prometheus, Grafana, Kubernetes и рабочие нагрузки ИИ.
Наблюдаемость — это основа надежных производственных систем.
Без метрик, дашбордов и оповещений кластеры Kubernetes дрейфуют, рабочие нагрузки ИИ и LLM молча отказывают, а регрессии задержек остаются незамеченными до тех пор, пока пользователи не пожаловаться.
От базового RAG до продакшена: чанкинг, векторный поиск, реранкинг и оценка — всё в одном руководстве.
Production-focused guide to building RAG systems: chunking, vector stores, hybrid retrieval, reranking, evaluation, and when to choose RAG over fine-tuning.
A performance engineering hub for running LLMs efficiently: runtime behavior, bottlenecks, benchmarks, and the real constraints that shape throughput and latency.
Strategic guide to hosting large language models locally with Ollama, llama.cpp, vLLM, or in the cloud. Compare tools, performance trade-offs, and cost considerations.
Управляйте данными и моделями с помощью саморазмещаемых ЛЛМ
Самостоятельное размещение LLM позволяет контролировать данные, модели и выводы — это практический путь к суверенитету ИИ для команд, предприятий и стран.
Запуск крупных языковых моделей локально обеспечивает вам конфиденциальность, возможность работы оффлайн и отсутствие затрат на API.
Этот бенчмарк раскрывает, чего именно можно ожидать от 14 популярных
LLMs на Ollama на RTX 4080.
Экосистема Rust бурно развивается, особенно в области инструментов для программирования на основе ИИ и терминальных приложений. Этот обзор анализирует самые популярные репозитории Rust на GitHub в этом месяце.
Экосистема Go продолжает процветать с инновационными проектами, охватывающими инструменты ИИ, самоуправляемые приложения и инфраструктуру разработчиков. Этот обзор анализирует самые популярные репозитории Go на GitHub в этом месяце.
vLLM — это высокопроизводительный, экономичный по памяти движок для вывода и развертывания больших языковых моделей (LLM), разработанный лабораторией Sky Computing Калифорнийского университета в Беркли.
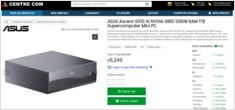
Актуальные цены в австралийских долларах от местных розничных продавцов уже доступны.
Компьютер
NVIDIA DGX Spark
(GB10 Grace Blackwell)
поступил в продажу в Австралии
у крупных розничных продавцов компьютеров с наличием на местных складах.
Если вы следите за
мировым ценообразованием и доступностью DGX Spark,
то вам будет интересно узнать, что в Австралии цены варьируются от 6 249 до 7 999 австралийских долларов в зависимости от конфигурации накопителей и конкретного продавца.
Техническое руководство по обнаружению контента, созданного с помощью ИИ
Распространение контента, созданного с помощью ИИ, создало новую проблему: различение подлинного человеческого текста и “AI slop” - низкокачественного, массово произведенного синтетического текста.
Безопасные с точки зрения типов выходные данные LLM с BAML и Instructor
При работе с большими языковыми моделями в производственной среде получение структурированных, типизированных выходных данных имеет критическое значение. Два популярных фреймворка - BAML и Instructor - предлагают разные подходы к решению этой проблемы.
Размышления об использовании больших языковых моделей для саморазмещаемого Cognee
Выбор лучшей LLM для Cognee требует баланса между качеством построения графов, уровнями галлюцинаций и ограничениями оборудования. Cognee лучше всего работает с крупными моделями с низким уровнем галлюцинаций (32B+) через Ollama, но средние варианты подходят для более легких настроек.