
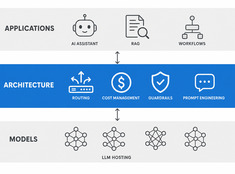
Architettura LLM: Progettazione del Sistema per l'IA in Produzione
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
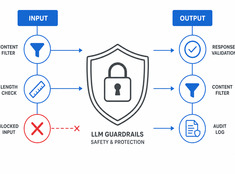
Controlla il rischio, non solo il modello.
I modelli di linguaggio di grandi dimensioni (LLM) sono imprevedibili. Possono allucinare, perdere dati, generare contenuti dannosi o rifiutare richieste legittime. I meccanismi di controllo (guardrails) vincolano il comportamento del modello senza sacrificare le sue capacità.
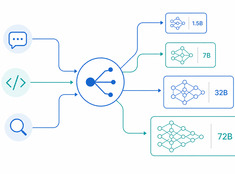
Il modello giusto per il compito giusto.
Eseguire un modello con 70 miliardi di parametri per riassumere un’email di 200 parole è uno spreco. Eseguire un modello da 3 miliardi di parametri per revisionare il codice in produzione è imprudente. La maggior parte dei sistemi si colloca da qualche punto intermedio: ed è qui che entra in gioco il routing dei modelli.
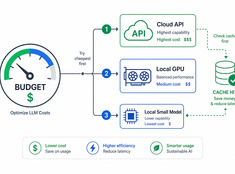
Spendi token dove contano davvero.
I costi degli LLM scala linearmente con l’utilizzo. Un sistema che elabora 10.000 richieste al giorno a $0,01 per richiesta costa $100 al giorno — 365 dollari l’anno. Su scala enterprise, si superano i $10.000.
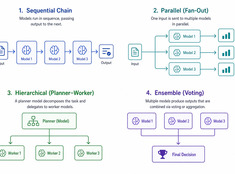
Scegli il pattern più semplice che funzioni.
I sistemi single-model sono semplici. I sistemi multi-model sono potenti. La sfida non consiste nel scegliere i modelli, ma nel progettare l’architettura che li orchestra.

Memoria di lavoro, strutturata e di recupero per gli assistenti.
La memoria trasforma gli assistenti da reattivi a persistenti, ma è anche il punto in cui molti sistemi si deteriorano silenziosamente. Le ricerche sostengono che la divisione tra memoria a breve e a lungo termine non sia più sufficiente per la memoria degli agenti moderni; gli SDK di OpenAI e LangGraph indicano un’architettura più semplice — memoria di lavoro, stato duraturo e recupero.

Come vengono costruiti effettivamente assistenti seri.
Un assistente AI di produzione non è “un LLM con un prompt”. È un sistema che accetta l’intento, mantiene lo stato, decide quando recuperare dati o eseguire azioni ed espone dettagli sufficienti a livello di runtime per eseguire il debug dei guasti.

L'IA cambia la gestione della conoscenza, non il suo scopo.
L’intelligenza artificiale non sta sostituendo la gestione della conoscenza; sta cambiando la sua forma sia per gli individui che per i team.
Stelle, token, download: chi vince davvero?
I framework open source per agenti AI stanno esplodendo di popolarità su GitHub. Due progetti al centro dell’ecosistema dei sistemi AI auto-ospitati — OpenClaw e Hermes Agent — hanno preso un tale vantaggio che il resto del settore si contende un lontano terzo posto.

MTP rispetto alla decodifica standard su RTX 4080 — benchmark reali
Ho testato le prestazioni di Speculative Decoding (Multi-Token Prediction, MTP) su Qwen 3.6 27B e 35B su una RTX 4080 con 16 GB di VRAM.

Memoria VRAM libera senza arrestare llama-server.
Modalità router di llama.cpp è uno dei cambiamenti più utili a llama-server degli ultimi anni. Fornisce finalmente agli operatori di LLM locali un’esperienza di gestione dei modelli vicina a quella che ci si aspetta da Ollama, mantenendo al contempo le prestazioni grezze e il controllo a basso livello che rendono llama.cpp meritevole di essere utilizzato in primo luogo.

Conoscenza compilata per sistemi di IA
La premessa è semplice: la conoscenza compilata è più riutilizzabile dei frammenti recuperati. RAG è diventata la risposta predefinita a una domanda semplice: come fornisco a un LLM l’accesso a conoscenze esterne?

Una mappa dei sistemi di conoscenza moderni
PKM, RAG, wiki, sistemi di memoria per l’IA e, ora, flussi di lavoro pratici assistiti dall’IA vengono spesso discussi come se risolvessero lo stesso problema. Non è così. Tutti hanno a che fare con la conoscenza, ma operano a livelli diversi:

Smetti di interpretare le vibrazioni. Convalida i contratti.
La maggior parte dei tutorial sull’output strutturato degli LLM è superficiale. Ti insegnano a chiedere JSON gentilmente e poi sperare che il modello si comporti correttamente. Quello non è convalida. È ottimismo con le parentesi graffe.

Riferimento per l'ottimizzazione di LLM agentic
Questa pagina è un riferimento pratico per la regolazione dell’inferenza di LLM agentic (temperatura, top_p, top_k, penalità e come interagiscono in flussi di lavoro multi-step e intensivi nell’uso di strumenti).

Parla con Hermes dal tuo telefono
Hai già chiacchierato con Hermes Agent dal tuo telefono usando il testo. Ora vuoi parlarci direttamente e ricevere risposte vocali. Questa è solitamente la mossa giusta, soprattutto se utilizzi già Hermes come assistente self-hosted persistente. Digitare prompt lunghi su uno schermo piccolo è lento e soggetto a errori.