
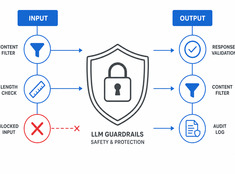
LLM Guardrails w praktyce: co naprawdę działa
Kontroluj ryzyko, nie tylko model.
Modele językowe LLM są nieprzewidywalne. Halucynują, ujawniają dane, generują szkodliwe treści lub odmawiają spełnienia legalnych zapytań. Mechanizmy ochronne (guardrails) ograniczają zachowanie modelu, nie kosztem jego możliwości.