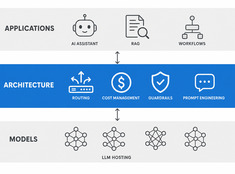
Architektura LLM: Projektowanie systemów dla AI w środowisku produkcyjnym
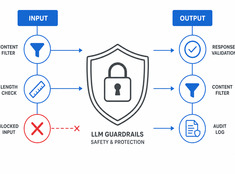
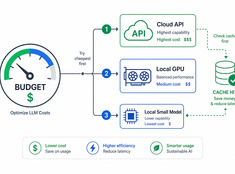
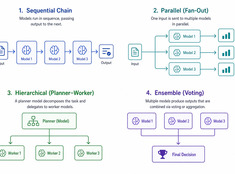
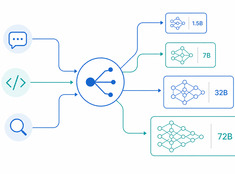
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.