

Padrão Saga em Transações Distribuídas - Com Exemplos em Go
Transações em Microserviços com o padrão Saga
O padrão Saga fornece uma solução elegante ao dividir transações distribuídas em uma série de transações locais com ações compensatórias.
Transações em Microserviços com o padrão Saga
O padrão Saga fornece uma solução elegante ao dividir transações distribuídas em uma série de transações locais com ações compensatórias.

Habilite a aceleração da GPU para o Docker Model Runner com suporte à NVIDIA CUDA
Docker Model Runner é a ferramenta oficial do Docker para executar modelos de IA localmente, mas habilitar a aceleração da GPU da NVidia no Docker Model Runner requer uma configuração específica.

Sistemas que preservam a privacidade com provas de conhecimento zero
Arquitetura de conhecimento zero representa uma mudança de paradigma em como projetamos sistemas que preservam a privacidade.

Guia completo de segurança - dados em repouso, em trânsito e em execução
Quando os dados são um ativo valioso, protegê-los nunca foi mais crítico.
Desde o momento em que a informação é criada até o ponto em que é descartada,
sua jornada está repleta de riscos — sejam armazenados, transferidos ou usados ativamente.
Compare headless CMS - funcionalidades, desempenho e casos de uso
Escolher o CMS headless certo pode fazer a diferença no seu estratégia de gestão de conteúdo. Vamos comparar três soluções open-source que influenciam como os desenvolvedores constroem aplicações orientadas por conteúdo.

Desenvolvimento de CLI em Go com os frameworks Cobra e Viper
Aplicações de interface de linha de comandos (CLI) são ferramentas essenciais para desenvolvedores, administradores de sistemas e profissionais de DevOps. Duas bibliotecas Go tornaram-se o padrão de fato para desenvolvimento de CLI em Go: Cobra para estrutura de comandos e Viper para gerenciamento de configuração.

Reduza os custos do LLM em 80% com otimização inteligente de tokens
A otimização de tokens é a habilidade crítica que separa as aplicações de LLM custo-efetivas das experiências que consomem orçamento.

Arquitetura orientada a eventos com AWS Kinesis para escala
AWS Kinesis tornou-se um pilar para a construção de arquiteturas modernas de microserviços orientadas a eventos, permitindo o processamento de dados em tempo real em grande escala com mínimo sobrecusto operacional.

Otimize APIs do frontend com GraphQL BFF e Apollo Server
O Backend for Frontend (BFF) combinado com GraphQL e Apollo Server cria uma arquitetura poderosa para aplicações web modernas.

Comandos do Elasticsearch para busca, indexação e análise
Elasticsearch é um poderoso motor de busca e análise distribuído construído sobre o Apache Lucene. Este cheatsheet abrangente abrange comandos essenciais, melhores práticas e referências rápidas para trabalhar com clusters Elasticsearch.

Construa servidores MCP para assistentes de IA com exemplos em Python
O Protocolo de Contexto do Modelo (MCP) está revolucionando a forma como os assistentes de IA interagem com fontes de dados externas e ferramentas. Neste guia, exploraremos como construir servidores MCP em Python, com exemplos focados nas capacidades de busca na web e raspagem.
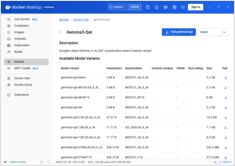
Referência rápida para comandos do Docker Model Runner
Docker Model Runner (DMR) é a solução oficial do Docker para executar modelos de IA localmente, introduzida em abril de 2025. Este guia rápido fornece uma referência rápida para todos os comandos essenciais, configurações e melhores práticas.
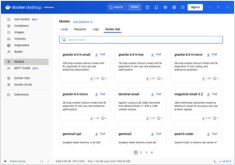
Compare Docker Model Runner e Ollama para LLM local
Executar modelos de linguagem grandes (LLMs) localmente tornou-se cada vez mais popular por motivos de privacidade, controle de custos e capacidades offline. O cenário mudou significativamente em abril de 2025, quando o Docker introduziu Docker Model Runner (DMR), sua solução oficial para implantação de modelos de IA.
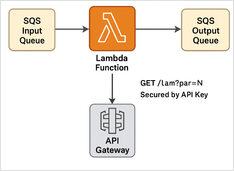
Exemplo passo a passo
Aqui temos um exemplo de Lambda em Python para processador de mensagens SQS + API REST com proteção por chave API + Terraform script para implantar em execução sem servidor.

Exemplos Específicos Utilizando Modelos de Linguagem Pensantes
Neste post, vamos explorar duas maneiras de conectar sua aplicação Python ao Ollama: 1. Via API REST HTTP; 2. Via a biblioteca oficial do Ollama para Python.

APIs ligeiramente diferentes exigem uma abordagem especial.
Aqui está uma comparação lado a lado de suporte para saída estruturada (obter JSON confiável de volta) entre provedores populares de LLM, juntamente com exemplos mínimos de Python