

Mistral Small, Gemma 2, Qwen 2.5, Mistral Nemo, LLama3 i Phi – test modeli językowych
Następny etap testów LLM
Nieco wcześniej wydano. Przejdźmy do sprawy i
testuj jak Mistral Small radzi sobie w porównaniu do innych LLM.
Następny etap testów LLM
Nieco wcześniej wydano. Przejdźmy do sprawy i
testuj jak Mistral Small radzi sobie w porównaniu do innych LLM.

Kod Pythona do ponownego rankingu w RAG.

Świetny nowy model AI do generowania obrazu na podstawie tekstu
Niedawno Black Forest Labs opublikowała zestaw modeli AI tekst-do-obrazu text-to-image AI models.
Te modele mają być znane z znacznie wyższej jakości wyjściowych obrazów.
Spróbujmy ich

Porównanie dwóch samodzielnie hostowanych silników wyszukiwania AI
Świetna jedzenie to przyjemność dla oczu również. Ale w tym poście porównamy dwa systemy wyszukiwania oparte na AI, Farfalle i Perplexica.
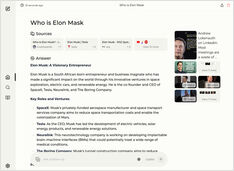
Uruchamianie lokalnego usługi w stylu Copilot? Łatwe!
To bardzo ekscytujące! Zamiast wołać copilot lub perplexity.ai i opowiadać światu, czego szukasz, teraz możesz uruchomić podobną usługę na własnym komputerze lub laptopie!

Testowanie wykrywania błędnego rozumowania
Niedawno widzieliśmy kilka nowych LLM, które zostały wydane. Wspaniałe czasy. Zróbmy test i zobaczmy, jak działają, gdy wykrywają błędy logiczne.
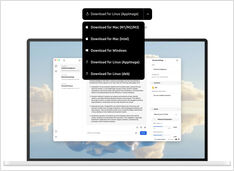
Nieco mniej do wyboru, ale nadal...
Kiedy zacząłem eksperymentować z LLM, interfejsy do nich były w aktywnym rozwoju, a teraz niektóre z nich są naprawdę dobre.

Wymaga pewnego doświadczenia, ale
Nadal istnieją pewne powszechne podejścia do pisania dobrych promptów, dzięki czemu LLM nie będzie się pogubił, próbując zrozumieć, czego od niego oczekujesz.

Często potrzebne fragmenty kodu w Pythonie
Czasami potrzebuję tego, ale nie mogę od razu znaleźć.
Więc trzymam je wszystkie tutaj.

Etykietowanie i trening wymaga pewnego stopnia łączenia
Kiedyś treningowałem detektor AI obiektów – LabelImg był bardzo pomocnym narzędziem, ale eksport z Label Studio do formatu COCO nie był akceptowany przez framework MMDetection..

8 wersji llama3 (Meta+) i 5 wersji phi3 (Microsoft) LLM
Testowanie zachowania modeli o różnej liczbie parametrów i różnym stopniu kwantyzacji.

Pliki modeli LLM Ollama zajmują dużo miejsca.
Po zainstalowaniu ollama lepiej natychmiast skonfigurować Ollama, aby przechowywał je w nowym miejscu. Wtedy, po pobraniu nowego modelu, nie zostanie on pobrany do starego lokalizacji.

Sprawdźmy prędkość LLM na GPU vs CPU
Porównanie prędkości przewidywania kilku wersji LLM: llama3 (Meta/Facebook), phi3 (Microsoft), gemma (Google), mistral (open source) na CPU i GPU.

Sprawdźmy jakość wykrywania błędów logicznych przez różne LLM-y
Oto porównanie kilku wersji LLM: Llama3 (Meta), Phi3 (Microsoft), Gemma (Google), Mistral Nemo (Mistral AI) oraz Qwen (Alibaba).