
Docker Model Runner チートシート: コマンドと例
Docker Model Runner コマンドのクイックリファレンス
Docker Model Runner (DMR) は、2025年4月に導入された Docker の公式ソリューションで、AIモデルをローカルで実行するためのものです。このチートシートでは、すべての必須コマンド、構成、およびベストプラクティスのクイックリファレンスを提供しています。
Docker Model Runner コマンドのクイックリファレンス
Docker Model Runner (DMR) は、2025年4月に導入された Docker の公式ソリューションで、AIモデルをローカルで実行するためのものです。このチートシートでは、すべての必須コマンド、構成、およびベストプラクティスのクイックリファレンスを提供しています。
Docker Model RunnerとOllamaを比較してみる:ローカルLLM向け
ローカルで大規模言語モデル(LLM)を実行する は、プライバシー、コスト管理、オフライン機能のためにますます人気になってきています。 2025年4月にDockerが**Docker Model Runner (DMR)**を導入し、AIモデルの展開用の公式ソリューションとして登場したことで、状況は大きく変わりました。

専用チップにより、AIの推論がより高速かつ低コストになっている。

6 カ国における実勢価格、Mac Studio との比較、および入手可能性について。
NVIDIA DGX Spark は実在する製品で、2025 年 10 月 15 日から販売開始されます。統合された NVIDIA AI スタック を利用して、ローカルでの LLM 作業 が必要な CUDA 開発者を主なターゲットとしています。米国での MSRP は 3,999 ドル です。英国・ドイツ・日本 での小売価格は、VAT(消費税)や流通チャネルの事情により高くなります。オーストラリアドル (AUD) や韓国ウォン (KRW) の公開価格はまだ広く発表されていません。

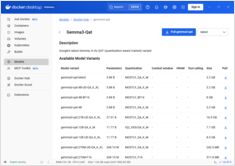
これらの2つのモデルの速度、パラメータ、および性能の比較
ここに Qwen3:30b と GPT-OSS:20b の比較を示します。指示の遵守とパフォーマンスのパラメータ、仕様、速度に焦点を当てています。

+ 思考型LLMを使用した具体的な例
この投稿では、PythonアプリケーションをOllamaに接続する2つの方法について紹介します。1つ目はHTTP REST APIを使用する方法、2つ目は公式のOllama Pythonライブラリを使用する方法です。

あまり良くない。
OllamaのGPT-OSSモデルは、LangChainやOpenAI SDK、vllmなどのフレームワークと使用する際に、構造化された出力を処理する際に繰り返し問題が発生しています。

わずかに異なるAPIには特別なアプローチが必要です。
以下は、提供されたHugoページコンテンツの日本語への翻訳です。すべてのHugoショートコードと技術要素は正確に保持されており、日本語の文法、表記、文化に合った表現が使用されています。
以下は、構造化された出力(信頼性の高いJSONを取得)をサポートする、人気のあるLLMプロバイダーの比較、および最小限のPythonの例です。

Ollamaから構造化された出力を得るいくつかの方法
大規模言語モデル(LLM) は強力ですが、実運用では自由な形式の段落はほとんど使いません。 代わりに、予測可能なデータ:属性、事実、またはアプリにフィードできる構造化されたオブジェクトを望みます。 それはLLM構造化出力です。

オラマモデルのスケジューリングに関する自分のテスト
ここでは、新しいバージョンのOllamaがモデルに対してどのくらいのVRAMを割り当てているかについて、Ollama VRAM割り当てと以前のOllamaバージョンを比較しています。新しいバージョンは、以前のバージョンよりも劣っています。

現在のOllama開発状況に対する私の見解
Ollama は、LLM をローカルで実行するためのツールとして、非常に人気のあるツールの一つとなっています。
シンプルな CLI と、モデル管理の簡素化により、クラウド外で AI モデルと仕事をしたい開発者にとっての定番のオプションとなっています。
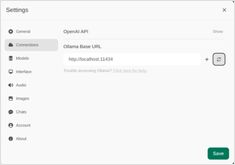
2025年のOllamaで最も注目されているUIの概要
ローカルにホストされた Ollama は、あなたのマシン上で大規模言語モデルを実行できるが、コマンドライン経由での使用はユーザーにとって使いにくい。
以下に、ローカルの Ollama に接続するための、いくつかのオープンソースプロジェクトが提供する ChatGPTスタイルのインターフェース がある。

2025 年 7 月にもまもなく利用可能となるでしょう。
Nvidia 社がNVIDIA DGX Sparkの発売を控えています。これは Blackwell アーキテクチャを採用した小型 AI スーパーコンピュータで、128GB 以上の統一メモリと 1 PFLOPS の AI 性能を備えています。LLM を実行するに最適なデバイスです。

GOにおけるMCP仕様と実装に関する長文記事
ここに、モデルコンテキストプロトコル(MCP)の説明が示されています。MCPサーバーの実装方法の短いノート(GoでのMCPサーバーの実装)も含まれており、メッセージ構造やプロトコル仕様についても記載されています。

RAG を実装中ですか?Go のコードスニペットを紹介 - 2 部目
標準の Ollama には直接的なリランク API がないため、クエリ - ドキュメントペアのエンベッディングを生成してスコアリングを行うことで、Go 言語による Qwen3 Reranker を使ったリランキング を実装する必要があります。

Qwen3 8B、14Bおよび30B、Devstral 24B、Mistral Small 24B
このテストでは、Ollama上でホストされているさまざまなLLMがHugoページを英語からドイツ語に翻訳する方法を比較しています。英語からドイツ語への翻訳。