
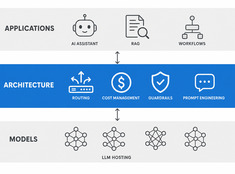
LLMのアーキテクチャ:本番運用向けAIのシステム設計
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
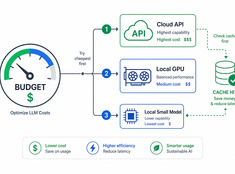
本当に重要な場所でトークンを活用しましょう。
LLMのコストは利用量に対して線形に比例して増加します。1日10,000リクエスト、1リクエストあたり0.01ドルで処理するシステムの場合、日額コストは100ドル、年間では365ドルになります。エンタープライズ規模では、それが1万ドルを超えます。
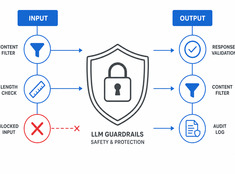
モデルだけでなく、リスクを管理せよ。
LLM(大規模言語モデル)は予測不可能な性質を持っています。ハルシネーション(幻覚)を起こしたり、データを漏洩させたり、有害なコンテンツを生成したり、正当なリクエストを拒否したりすることがあります。ガードレール(安全策)は、モデルの機能を損なうことなく、その振る舞いを制限します。
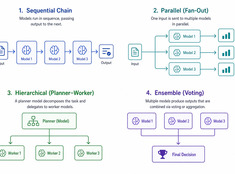
「機能する最もシンプルなパターンを選びましょう。」
シングルモデルのシステムはシンプルです。マルチモデルのシステムは強力です。課題はモデルを選ぶことではなく、それらを調整するアーキテクチャを設計することにあります。
適切なタスクに最適なモデル。
700億パラメータのモデルを使って200語のメールを要約するのは無駄です。30億パラメータのモデルで本番環境のコードレビューを行うのは無謀です。多くのシステムはその中間に位置しており、そこがモデルルーティングの登場シーンです。

アシスタントのためのワーキングメモリ、構造化メモリ、および検索メモリ
メモリはアシスタントを反応型から永続型へと変えますが、同時に多くのシステムが静かに劣化してしまう箇所でもあります。調査では、短期的メモリと長期的メモリの二分法是では現代のエージェントメモリには不十分であると指摘されています。OpenAIやLangGraphのSDKは、よりシンプルな構成、つまりワーキングメモリ、永続的な状態、および検索による取得(リトリーブ)へと焦点を移しています。

実際に本格的なアシスタントはどのように構築されているか
本番環境向けのAIアシスタントは「プロンプト付きのLLM」ではありません。インテント(意図)を受け付け、状態を保持し、いつ検索を実行すべきか、いつ行動すべきかを決定し、障害のデバッグに必要なランタイムの詳細を公開するシステムなのです。

AIは知識管理の目的を変えず、手法を変革する。
AIは知識管理を置き換えるものではありません。むしろ、個人およびチームにとって知識管理の形そのものを変革しています。
スター、トークン、ダウンロード—who actually wins?
オープンソースのAIエージェントフレームワークは、GitHub上でその人気を急速に高めています。セルフホスト型AIシステムのエコシステムの中核をなす2つのプロジェクト、OpenClawとHermes Agentは、他を大きく引き離し、残りのライバルたちは遠い3位の座を争う状況になっています。

RTX 4080におけるMTPと標準デコーディングの比較 — 実ベンチマーク
RTX 4080(16 GB VRAM)環境で、Qwen 3.6 27Bおよび35Bにおける推論デコーディング(マルチトークン予測、MTP)のパフォーマンスをテストしました。

llama-serverを停止せずにVRAMを解放する方法
llama.cpp ラーターモード は、llama-server における数年間で最も有用な変更の一つです。これにより、ローカルLLM運用者は、Ollamaで期待されるようなモデル管理体験に近いものをようやく手に入れることができました。同時に、llama-server を使い続ける価値がある生のパフォーマンスと低レベルの制御も維持されています。

AIシステム向けの構造化された知識
前提はシンプルです。コンパイルされた知識は、取得された断片的な情報よりも再利用性が高いというものです。 RAG(検索強化生成)は、LLM(大規模言語モデル)に外部知識へのアクセスをどのように与えるかという直接的な問いに対するデフォルトの答えとなりました。

「雰囲気」に頼る解析をやめ、契約を検証せよ。
ほとんどのLLM「構造化出力」チュートリアルは、本気度にかけるものです。 それらは、JSONを丁寧な口調でリクエストし、モデルが適切に動作することを祈る方法を教えます。 それでは検証ではありません。 それは単に括弧で囲まれた楽観主義にすぎません。

エージェント型LLMのチューニングに関する参照資料
このページは、エージェント型LLM推論チューニングの実用的なリファレンス(temperature、top_p、top_k、ペナルティ、およびマルチステップやツール多用なワークフローにおけるそれらの相互作用)です。
より広範なLLMパフォーマンスエンジニアリングハブと併せて参照し、明確なLLMホスティングとサービングの概要と組み合わせることで、モデルがリソース不足に陥った際にはスループットとスケジューリングが依然として支配的ですが、不安定なサンプリングはGPUが処理を終える前にリトライと出力トークンを消費してしまうことがわかります。
このページでは以下をまとめます:

スマートフォンからHermesと会話する
スマートフォンからテキストでヘルメスエージェントとチャットすることはすでに可能でしょう。 今、あなたはエージェントと直接会話し、音声で返信を受け取りたいと考えています。 これは通常、正しい選択です。特にHermesを永続的な自己ホスト型アシスタントとして使用している場合には顕著です。 小さな画面で長いプロンプトをタイプするのは、時間がかかり、誤りも生じやすいものです。

セルフホスト型LLMにおけるHermesカーンボードの負荷を制御する
Hermes AgentにはKanbanスタイルのボードとHermes Gatewayが標準で搭載されていますが、一度に多数のタスクがディスパッチされると、セルフホスト型のLLMが過負荷状態に陥る可能性があります。