

Ollama と Qwen3 Reranker モデルを用いたドキュメントの再評価 - Go での実装
RAG を実装中ですか?Go のコードスニペットを紹介 - 2 部目
標準の Ollama には直接的なリランク API がないため、クエリ - ドキュメントペアのエンベッディングを生成してスコアリングを行うことで、Go 言語による Qwen3 Reranker を使ったリランキング を実装する必要があります。
RAG を実装中ですか?Go のコードスニペットを紹介 - 2 部目
標準の Ollama には直接的なリランク API がないため、クエリ - ドキュメントペアのエンベッディングを生成してスコアリングを行うことで、Go 言語による Qwen3 Reranker を使ったリランキング を実装する必要があります。
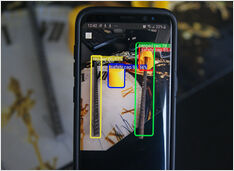
以前、オブジェクト検出AIのトレーニングを行いました。
ある寒い冬の7月の日… その日はオーストラリアにいた… 私は、未封のコンクリート補強筋を検出するためのAIモデルを訓練するという緊急の必要性を感じた…

Qwen3 8B、14Bおよび30B、Devstral 24B、Mistral Small 24B
このテストでは、Ollama上でホストされているさまざまなLLMがHugoページを英語からドイツ語に翻訳する方法を比較しています。英語からドイツ語への翻訳。

RAG の実装ですね。Golang 用のコードスニペットをいくつか紹介します。
この小さな Reranking Go コード例は、クエリと各候補ドキュメントの埋め込みを生成するために Ollama を呼び出し、 その後、コサイン類似度で降順にソートします。

LLM用に2番目のGPUをインストールすることを考慮していますか?
PCIe レーンがLLM性能に与える影響? タスクによります。トレーニングやマルチGPUの推論では、パフォーマンスの低下が顕著です。

LLMでHTMLからテキストを抽出する...
Ollama モデルライブラリには、HTML コンテンツを Markdown に変換できるモデルが存在します。これはコンテンツ変換タスクに役立ちます。このガイドは、2026年のドキュメンテーションツール: Markdown、LaTeX、PDFおよび印刷ワークフロー ハブの一部です。

それらの違いはどのくらいでしょうか?

カーソルAI vs ジョイブコパイロット vs クラインAI vs...
いくつかのAI支援によるコーディングツールおよびAIコーディングアシスタントとその魅力的な特徴について紹介します。

LLMプロバイダーの短いリスト
LLMを使用することは非常に高価ではありません。新しい高性能なGPUを購入する必要がないかもしれません。LLMプロバイダーの一覧は、クラウド上のLLMプロバイダー で確認できます。それぞれが提供しているLLMについても記載されています。

インテルCPUにおけるOllamaの効率的なコアとパフォーマンスコアの比較
私はある仮説をテストしたいと思っています。すなわち、「インテルCPUのすべてのコアを活用することで、LLMの速度が向上するか?」というものです。このテストについては、ALL cores on Intel CPU would raise the speed of LLMs?をご覧ください。
新しいgemma3 27bitモデル(gemma3:27b、ollama上では17GB)が私のGPUの16GB VRAMに収まらず、部分的にCPU上での実行に頼っているという点が気になります。

AIは多くのパワーが必要です…
現代の世界の混乱の中でも、ここではさまざまなカードのテクスペックを比較、AIタスクに適したAI用のカードについて見ていく。
(Deep Learning、
Object Detection、
およびLLMs)。
しかし、これらはすべて非常に高価です。

オラマを並列リクエストの実行に設定する。
Ollama サーバーが同時に2つのリクエストを受け取った場合、その動作は設定と利用可能なシステムリソースに依存します。

このトレンドのAI支援型コーディングとは何か?
Vibe coding は、開発者が自然言語で望む機能を説明し、AIツールが自動的にコードを生成するという、AI駆動型のプログラミングアプローチです。

MM* ツールのフルセットは EOL となっています...
私はMMDetection (mmengine, mdet, mmcv)をかなり使い、
今ではそのゲームから出てしまったようです。
残念です。私はそのモデルズーが好きでした。

2つのdeepseek-r1モデルを2つのベースモデルと比較する
DeepSeekの 1世代目の推論モデルで、OpenAI-o1と同等の性能を備えています。 これは、LlamaおよびQwenに基づいてDeepSeek-R1から蒸留された6つの密結合モデルです。

更新されたOllamaコマンド一覧 - ls, ps, run, serve など
このOllama CLI チェックリストは、ollama ls、ollama serve、ollama run、ollama ps、モデル管理、および一般的なワークフローに焦点を当てており、コピー/ペーストできる例も含まれています。