

Ollama、llama.cpp用のClaude Codeのインストールと設定、および料金
ローカルモデルバックエンドに対応したエージェンティックコーディング
Claude Codeは、マーケティングが上手な自動補完ツールではありません。これはエージェント型コーディングツールです。コードベースを読み取り、ファイルを編集し、コマンドを実行し、開発ツールと統合します。
ローカルモデルバックエンドに対応したエージェンティックコーディング
Claude Codeは、マーケティングが上手な自動補完ツールではありません。これはエージェント型コーディングツールです。コードベースを読み取り、ファイルを編集し、コマンドを実行し、開発ツールと統合します。

開発者向けHermesエージェントのインストールとクイックスタート
Hermes Agent は、ローカルマシンや低コストのVPS上で稼働する、モデル非依存の自己ホスト型AIアシスタントです。ターミナルおよびメッセージングインターフェースを通じて動作し、反復的なタスクを再利用可能なスキルに変換することで、時間とともに性能を向上させます。

TGI をインストールし、迅速にデプロイ、さらに高速にデバッグ。
Text Generation Inference (TGI) は、非常に特有の雰囲気を持っています。 推論の分野で最も新しい子供ではありませんが、すでに本番環境でのトラブルを学び、その教訓をデフォルト設定に焼き付けているのが TGI です。

16 GB VRAMにおけるllama.cppのトークン処理速度(表)。
ここでは、16GBのVRAMを搭載したGPUで動作するいくつかのLLMの速度を比較し、セルフホスティング向けの最適なモデルを選択しています。
llama.cppを使用して、19K、32K、および64KトークンのコンテキストウィンドウでこれらのLLMを実行しました。
VRAMブロックとベンチマークスタイルのチャートが特徴的なスタイリッシュなGPU
この投稿では、速度の観点から可能な限り高いパフォーマンスを引き出すための試行錯誤を記録しています。
| モデル | サイズ | 19K VRAM | 19K GPU/CPU | 19K T/s | 32K VRAM | 32K ロード | 32K T/s | 64K VRAM | 64K ロード | 64K T/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3.6-35B-A3B-UD-IQ3_XXS | 13.2 | 13.8GB | 96%/100% | 147.5 | 14.0GB | 96%/101% | 149.1 | 14.7GB | 96%/101% | 145.8 |
| Qwen3.6-35B-A3B-UD-IQ4_XS | 17.7 | 14.3GB | 62%/266% | 95.0 | 14.9GB | 58%/279% | 92.3 | 14.9GB | 57%/293% | 86.4 |
| Qwen3.5-35B-A3B-UD-IQ3_S | 13.6 | 14.3GB | 93%/100% | 136.4 | 14.6GB | 93%/100% | 138.5 | 14.9GB | 88%/115% | 136.8 |
| Qwen3.5-27B-IQ3_XXS-bartowsky | 11.3 | 12.8 | 98/100 | 44.9 | 13.5 | 98/100 | 44.9 | 14.5 | 45/415 | 23.6 |
| Qwen3.5-27B-UD-IQ3_XXS | 11.5 | 12.9 | 98/100 | 45.3 | 13.7 | 98/100 | 45.1 | 14.7 | 45/410 | 22.7 |
| Qwen3.5-27B-IQ4_XS.gguf | 15.0 | 14.6 | 49/406 | 20.5 | 14.7 | 37/465 | 17.4 | 14.7 | 23/533 | 13.3 |
| Qwen3.5-122B-A10B-UD-IQ3_XXS | 44.7 | 14.7 | 30/470 | 22.3 | 14.7 | 30/480 | 21.8 | 14.7 | 28/490 | 21.5 |
| Qwen3.5-122B-A10B-UD-IQ3_S | 46.5 | 14.7 | 25/516 | 19.4 | 14.7 | 24/516 | 19.5 | 14.7 | 24/516 | 19.6 |
| Mistral-Small-4-119B UD-IQ3_XXS | 42.8 | 14.8 | 28/585 | 30.4 | 14.7 | 27/574 | 28.5 | 14.9 | 20/590 | 31.5 |
| Qwen3-Coder-Next-UD-IQ4_XS | 38.4 | 14.6 | 32/460 | 41.1 | 14.7 | 29/440 | 41.3 | 14.8 | 32/460 | 38.3 |
| Nemotron Super 120b IQ3_XXS | 56.2 | 15.0 | 26/517 | 17.5 | 14.6 | 26/531 | 17.4 | 14.6 | 26/535 | 17.6 |
| gemma-4-26B-A4B-it-UD-IQ4_XS | 13.4 | 14.7 | 95/100 | 121.7 | 14.9 | 95/115 | 114.9 | 14.9 | 75/190 | 96.1 |
| gemma-4-31B-it-UD-IQ3_XXS | 11.8 | 14.8 | 68/287 | 29.2 | 14.8 | 41/480 | 18.4 | 14.8 | 18/634 | 8.1 |
| GLM-4.7-Flash-IQ4_XS | 16.3 | 15.0 | 66/240 | 91.8 | 14.9 | 62/262 | 86.1 | 14.9 | 53/313 | 72.5 |
| GLM-4.7-Flash-REAP-23B IQ4_XS | 12.6 | 13.7 | 92/100 | 122.0 | 14.4 | 95/102 | 123.2 | 14.9 | 71/196 | 97.1 |
19K、32K、64Kはコンテキストのサイズを示します。

GPU および永続性を備えた Compose ファーストの Ollama サーバー。
Ollama は、メタル(物理マシン)上で非常に良好に動作します。それをサービスとして扱うと、さらに興味深くなります。安定したエンドポイント、固定されたバージョン、永続的なストレージ、そして GPU が利用可能か不可かの明確な状態が確保されます。
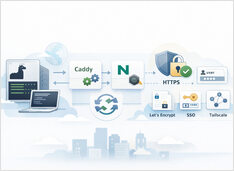
ストリーミング応答を破綻させずに HTTPS で Ollama を利用する。
リバースプロキシの背後で Ollama を実行することは、HTTPS、オプションのアクセス制御、予測可能なストリーミング動作を実現する最も簡単な方法です。

SGLang を使ってオープンモデルを高速に提供。
SGLang は、大規模言語モデルおよびマルチモーダルモデル向けの高パフォーマンスなサービングフレームワークであり、単一の GPU から分散クラスターに至るまで、低レイテンシかつ高スループットの推論を提供するために設計されています。

クライアントを変更せずにホットスワップ可能なローカル LLM。
まもなく vLLM や llama.cpp など、それぞれのスタックが独自のポートで稼働している状態に陥ります。下流のシステムはすべて**/v1というベース URL を求めるため、ポート、プロファイル、ワンオフスクリプトを頻繁に変更することになります。llama-swapは、これらのスタックの前に配置される/v1**プロキシです。

地元のAIセットアップの多くは、モデルとランタイムから始まります。

Ultrawork を実行した際に実際には何が起こるのでしょうか。
Oh My Opencode は「仮想 AI 開発チーム」を約束しています。Sisyphus が専門家を指揮し、タスクが並列で実行され、ultrawork という魔法のようなキーワードがそのすべてを活性化させます。

Oh My Opencode をインストールして、より高速にリリースしましょう。
Oh My Opencode は、OpenCode をマルチエージェントコーディングハネスへと変えます。オーケストレーターは、並行して実行される専門エージェントに作業を委任します。

OpenCode LLM テスト — コーディングおよび精度の統計
Ollama と llama.cpp でローカルホストされている複数の LLM と、比較のために追加した OpenCode Zen の無料モデルとの組み合わせで、OpenCode がどのように動作するかをテストしました。

シジフォスとその専門エージェントチームをご紹介します。
OpenCode の最大の能力向上は、専門化されたエージェントによるものです:オーケストレーション、計画、実行、調査の意図的な分離です。

OpenHands CLI を数分でクイックスタート
OpenHands は、AI 駆動のソフトウェア開発エージェントのためのオープンソースでモデル非依存のプラットフォームです。 単なる自動補完ツールではなく、エージェントがコーディングパートナーのように振る舞うことを可能にします。

数分で LocalAI を使用して、OpenAI 互換 API をセルフホストできます。
LocalAI は、ご自身のハードウェア(ノート PC、ワークステーション、オンプレミスサーバー)上で AI ワークロードを実行できるように設計された、自己完結型でローカルファーストの推論サーバーです。これは、OpenAI API と互換性のある「差し替え可能な」APIとして動作します。

「OpenCode」のインストール、設定、および使用方法
ローカル推論には、llama.cpp を使い続けています。Ollama や他のツールが抽象化している部分を自分で制御できるためであり、単に「動く」だけでなく、GGUF モデルを llama-cli で対話的に実行したり、llama-server で OpenAI 互換の HTTP API を公開したりするのが簡単だからです。