
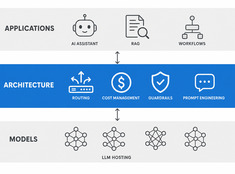
Architecture des LLM : Conception de systèmes pour l'IA en production
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
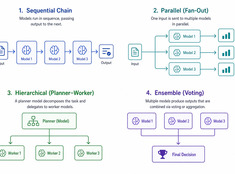
« Choisissez le motif le plus simple qui fonctionne. »
Les systèmes à modèle unique sont simples. Les systèmes multi-modèles sont puissants. Le défi ne réside pas dans le choix des modèles, mais dans la conception de l’architecture qui les orchestre.
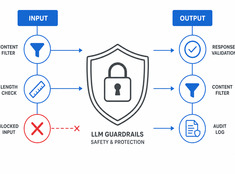
Contrôlez le risque, pas seulement le modèle.
Les LLM sont imprévisibles. Ils hallucinent, fuient des données, génèrent du contenu nuisible ou refusent des demandes légitimes. Les garde-fous contraignent le comportement du modèle sans sacrifier ses capacités.
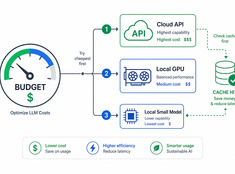
Dépensez les jetons là où ils comptent vraiment.
Les coûts des LLM évoluent de manière linéaire avec l’utilisation. Un système traitant 10 000 requêtes par jour à 0,01 $ par requête coûte 100 $ par jour, soit 365 $ par an. À l’échelle de l’entreprise, cela représente plus de 10 000 $.
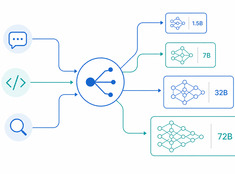
Le bon modèle pour la bonne tâche.
Exécuter un modèle de 70 milliards de paramètres pour résumer un e-mail de 200 mots est un gaspillage. Utiliser un modèle de 3 milliards de paramètres pour passer en revue du code en production est négligent. La plupart des systèmes se situent quelque part entre les deux — et c’est là qu’intervient le routage de modèles.

Mémoire de travail, structurée et de récupération pour les assistants.
La mémoire transforme les assistants d’entités réactives en entités persistantes, mais c’est aussi là que de nombreux systèmes pourrissent silencieusement. Les enquêtes soutiennent que la distinction entre mémoire à court terme et à long terme n’est plus suffisante pour la mémoire des agents modernes ; les SDKs OpenAI et LangGraph pointent vers une pile plus simple — mémoire de travail, état durable et récupération.

Comment les assistants sérieux sont réellement conçus.
Un assistant IA de production n’est pas « un LLM avec un prompt ». C’est un système qui accepte l’intention, maintient un état, décide quand récupérer des informations ou agir, et expose suffisamment de détails d’exécution pour déboguer les échecs.

L'IA transforme la gestion des connaissances, mais pas son but.
L’IA ne remplace pas la gestion des connaissances ; elle en modifie la forme, tant pour les individus que pour les équipes.
Étoiles, jetons, téléchargements : qui est vraiment gagnant ?
Les frameworks d’agents IA open-source connaissent une popularité explosive sur GitHub. Deux projets au cœur de l’écosystème des systèmes IA auto-hébergés — OpenClaw et Hermes Agent — ont pris une telle avance que le reste du domaine se bat pour une lointaine troisième place.

MTP vs décodage standard sur RTX 4080 — benchmarks réels
J’ai testé les performances de la décodage spéculatif (Multi-Token Prediction, MTP) sur les modèles Qwen 3.6 27B et 35B avec une RTX 4080 dotée de 16 Go de VRAM.

Libérer de la VRAM sans interrompre llama-server.
Mode routeur de llama.cpp est l’un des changements les plus utiles apportés à llama-server depuis des années. Il offre enfin aux opérateurs de LLM locaux une expérience de gestion des modèles proche de celle attendue d’Ollama, tout en conservant les performances brutes et le contrôle de bas niveau qui rendent llama.cpp intéressant à utiliser en premier lieu.

Connaissances compilées pour les systèmes d'IA
Le principe est simple : les connaissances compilées sont plus réutilisables que les fragments récupérés. RAG est devenu la réponse par défaut à une question simple : comment donner à un LLM (modèle de langage) l’accès à des connaissances externes ?

Arrêtez d’interpréter des vibes. Validez les contrats.
La plupart des tutoriels sur les « sorties structurées » des LLM manquent de sérieux. Ils vous apprennent à demander du JSON poliment, puis à espérer que le modèle se comporte correctement. Ce n’est pas de la validation. C’est de l’optimisme entre accolades.

Référence pour l’ajustement des LLM agencés
Cette page est une référence pratique pour l’optimisation de l’inférence des LLMs agents (température, top_p, top_k, pénalités, et comment ils interagissent dans les flux de travail multi-étapes et intensifs en outils).

Parlez à Hermes depuis votre téléphone
Vous discutez déjà avec l’agent Hermes depuis votre téléphone par messages texte. Vous souhaitez désormais lui parler directement et recevoir des réponses vocales. C’est généralement la bonne approche, surtout si vous utilisez déjà Hermes comme assistant auto-hébergé persistant. Taper de longs prompts sur un petit écran est lent et sujet aux erreurs.

Gérez la charge Kanban d'Hermès sur votre LLM auto-hébergé.
Hermes Agent est livré avec un tableau Kanban et la passerelle Hermes qui peuvent saturer votre LLM auto-hébergé si trop de tâches sont expédiées simultanément.