
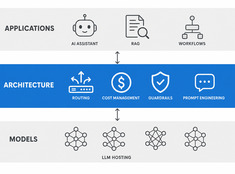
LLM Architecture: System Design for Production AI
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
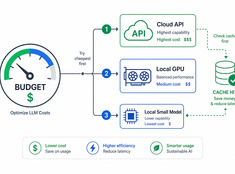
Spend tokens where they actually matter.
LLM costs scale linearly with usage. A system processing 10,000 requests a day at $0.01 per request costs $100 daily — $365 a year. At enterprise scale, that’s over $10,000.
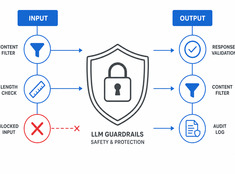
Control the risk, not just the model.
LLMs are unpredictable. They hallucinate, leak data, generate harmful content, or refuse legitimate requests. Guardrails constrain model behavior without sacrificing capability.
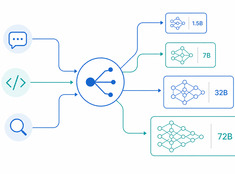
The right model for the right task.
Running a 70B parameter model to summarize a 200-word email is wasteful. Running a 3B model to review production code is reckless. Most systems live somewhere in between — and that’s where model routing comes in.
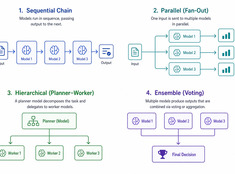
Pick the simplest pattern that works.
Single-model systems are simple. Multi-model systems are powerful. The challenge isn’t choosing models — it’s designing the architecture that orchestrates them.

Working, structured, and retrieval memory for assistants.
Memory turns assistants from reactive to persistent, but it is also where many systems quietly rot. Surveys argue the short-term versus long-term split is no longer enough for modern agent memory; OpenAI and LangGraph SDKs point to a simpler stack — working memory, durable state, and retrieval.

How serious assistants are actually built.
A production AI assistant is not “an LLM with a prompt”. It is a system that accepts intent, keeps state, decides when to retrieve or act, and exposes enough runtime detail to debug failures.

AI changes knowledge management, not its purpose.
AI is not replacing knowledge management; it is changing the shape of it for both individuals and teams.
Stars, tokens, downloads — who actually wins?
Open-source AI agent frameworks are exploding in popularity on GitHub. Two projects at the core of the self-hosted AI systems ecosystem — OpenClaw and Hermes Agent — have pulled so far ahead that the rest of the field is fighting for a distant third place.

MTP vs standard decoding on RTX 4080 — real benchmarks
I tested Speculative decoding (Multi-Token Prediction, MTP) performance in Qwen 3.6 27B and 35B on an RTX 4080 with 16 GB VRAM.

Free VRAM without killing llama-server.
llama.cpp router mode is one of the most useful changes to llama-server in years. It finally gives local LLM operators something close to the model management experience people expect from Ollama, while keeping the raw performance and low-level control that make llama.cpp worth using in the first place.

Compiled knowledge for AI systems
The premise is simple: compiled knowledge is more reusable than retrieved fragments. RAG became the default answer to a straightforward question - how do I give an LLM access to external knowledge?

Stop parsing vibes. Validate contracts.
Most LLM “structured output” tutorials are unserious. They teach you to ask for JSON politely and then hope the model behaves. That is not validation. That is optimism with braces.

Agentic LLM tuning reference
This page is a practical reference for agentic LLM inference tuning (temperature, top_p, top_k, penalties, and how they interact in multi-step and tool-heavy workflows).

Talk to Hermes from your phone
You already chat to Hermes Agent from your phone with text. Now you want to talk to it directly and get spoken replies back. That is usually the right move, especially if you already use Hermes as a persistent self-hosted assistant. Typing long prompts on a small screen is slow and error-prone

Control Hermes Kanban load on your self hosted LLM.
Hermes Agent ships with a Kanban-style board and the Hermes Gateway that can saturate your self-hosted LLM if too many tasks are dispatched at once.