Тест OpenCode LLM — статистика написания кода и точности
Я протестировал, как работает OpenCode с несколькими локальными LLM на базе Ollama, и для сравнения добавил несколько бесплатных моделей из OpenCode Zen.
OpenClaw — это самоуправляемый AI-ассистент, предназначенный для работы с локальными LLM-движками, такими как Ollama, или с облачными моделями, такими как Claude Sonnet.
A performance engineering hub for running LLMs efficiently: runtime behavior, bottlenecks, benchmarks, and the real constraints that shape throughput and latency.
Strategic guide to hosting large language models locally with Ollama, llama.cpp, vLLM, or in the cloud. Compare tools, performance trade-offs, and cost considerations.
Управляйте данными и моделями с помощью саморазмещаемых ЛЛМ
Самостоятельное размещение LLM позволяет контролировать данные, модели и выводы — это практический путь к суверенитету ИИ для команд, предприятий и стран.
Запуск крупных языковых моделей локально обеспечивает вам конфиденциальность, возможность работы оффлайн и отсутствие затрат на API.
Этот бенчмарк раскрывает, чего именно можно ожидать от 14 популярных
LLMs на Ollama на RTX 4080.
Экосистема Go продолжает процветать с инновационными проектами, охватывающими инструменты ИИ, самоуправляемые приложения и инфраструктуру разработчиков. Этот обзор анализирует самые популярные репозитории Go на GitHub в этом месяце.
Актуальные цены в австралийских долларах от местных розничных продавцов уже доступны.
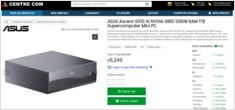
Компьютер
NVIDIA DGX Spark
(GB10 Grace Blackwell)
поступил в продажу в Австралии
у крупных розничных продавцов компьютеров с наличием на местных складах.
Если вы следите за
мировым ценообразованием и доступностью DGX Spark,
то вам будет интересно узнать, что в Австралии цены варьируются от 6 249 до 7 999 австралийских долларов в зависимости от конфигурации накопителей и конкретного продавца.
Безопасные с точки зрения типов выходные данные LLM с BAML и Instructor
При работе с большими языковыми моделями в производственной среде получение структурированных, типизированных выходных данных имеет критическое значение. Два популярных фреймворка - BAML и Instructor - предлагают разные подходы к решению этой проблемы.
Размышления об использовании больших языковых моделей для саморазмещаемого Cognee
Выбор лучшей LLM для Cognee требует баланса между качеством построения графов, уровнями галлюцинаций и ограничениями оборудования. Cognee лучше всего работает с крупными моделями с низким уровнем галлюцинаций (32B+) через Ollama, но средние варианты подходят для более легких настроек.
Библиотека Python для Ollama теперь включает в себя нативные возможности поиска в интернете с Ollama. С несколькими строками кода вы можете дополнить свои локальные LLMs актуальной информацией из интернета, снижая вероятность галлюцинаций и повышая точность.
Ollama’s Web Search API позволяет дополнять локальные LLMs актуальной информацией из интернета. Это руководство показывает, как реализовать возможности веб-поиска на Go, от простых API-запросов до полнофункциональных поисковых агентов.
Сравните лучшие локальные инструменты хостинга LLM в 2026 году. Зрелость API, поддержка оборудования, вызов инструментов и реальные сценарии использования.
Запуск локальных языковых моделей (LLM) теперь практичен для разработчиков, стартапов и даже корпоративных команд. Но выбор правильного инструмента — Ollama, vLLM, LM Studio, LocalAI или других — зависит от ваших целей:
Развертывание корпоративного ИИ на бюджетном оборудовании с использованием открытых моделей.
Демократизация искусственного интеллекта уже здесь.
С появлением открытых LLM, таких как Llama, Mistral и Qwen, которые теперь не уступают проприетарным моделям, команды могут создавать мощную инфраструктуру ИИ на потребительском оборудовании — значительно сокращая расходы при сохранении полного контроля над конфиденциальностью данных и развертыванием.