
Модели Qwen3 Embedding & Reranker в Ollama: передовые достижения в производительности
Новые потрясающие LLM доступны в Ollama
Модели Qwen3 Embedding и Reranker являются последними выпусками в семействе Qwen, специально разработанными для продвинутых задач встраивания текста, извлечения и повторного ранжирования.
Радость для глаза
Модели Qwen3 Embedding и Reranker представляют собой значительный прорыв в области многоязычной обработки естественного языка (NLP), обеспечивая передовые результаты в задачах встраивания и повторного ранжирования текста. Эти модели, входящие в серию Qwen, разработанные Alibaba, предназначены для поддержки широкого круга приложений, от семантического поиска до поиска кода. Хотя Ollama является популярной открытой платформой для размещения и развертывания крупных языковых моделей (LLM), интеграция моделей Qwen3 с Ollama не описана подробно в официальной документации. Однако модели доступны через Hugging Face, GitHub и ModelScope, что позволяет потенциально развернуть их локально с помощью Ollama или подобных инструментов.
Примеры использования этих моделей
Пожалуйста, посмотрите примеры кода на Go с использованием ollama и этих моделей:
- Повторное ранжирование текстовых документов с использованием Ollama и модели Qwen3 Embedding - на Go
- Повторное ранжирование текстовых документов с использованием Ollama и модели Qwen3 Reranker - на Go
Обзор новых моделей Qwen3 Embedding и Reranker на Ollama
Эти модели теперь доступны для развертывания на Ollama в различных размерах, обеспечивая передовые результаты и гибкость для широкого круга приложений, связанных с языком и кодом.
Ключевые особенности и возможности
-
Размеры моделей и гибкость
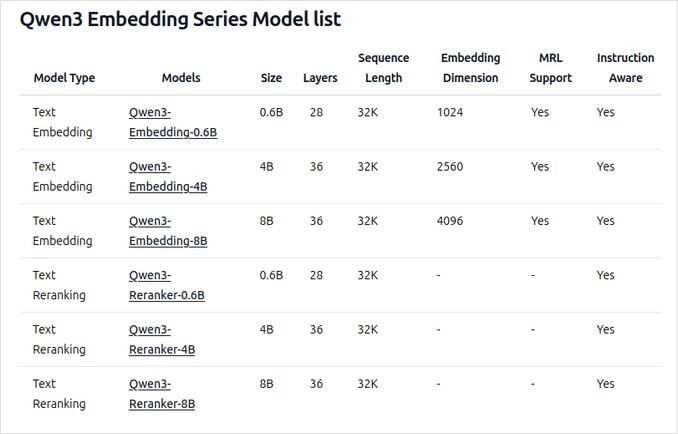
- Доступны в нескольких размерах: 0.6B, 4B и 8B параметров для задач встраивания и повторного ранжирования.
- 8B модель встраивания на данный момент занимает первое место в рейтинге MTEB для многоязычных моделей (по состоянию на 5 июня 2025 года с оценкой 70.58).
- Поддерживает широкий выбор опций квантования (Q4, Q5, Q8 и т.д.) для балансировки производительности, использования памяти и скорости. Q5_K_M рекомендуется большинству пользователей, так как сохраняет большинство производительности модели, при этом эффективно используя ресурсы.
-
Архитектура и обучение
- Построены на основе Qwen3, используя как архитектуру двойного кодера (для встраивания), так и архитектуру перекрестного кодера (для повторного ранжирования).
- Модель встраивания: обрабатывает отдельные текстовые фрагменты, извлекая семантические представления из конечного скрытого состояния.
- Модель повторного ранжирования: принимает пары текста (например, запрос и документ) и выдает оценку релевантности с использованием подхода перекрестного кодера.
- Модели встраивания используют трехэтапную парадигму обучения: контрастное предобучение, надзорное обучение с высококачественными данными и объединение моделей для оптимальной обобщаемости и адаптируемости.
- Модели повторного ранжирования обучаются напрямую с использованием высококачественных помеченных данных для эффективности и эффективности.
-
Многоязычность и поддержка нескольких задач
- Поддерживают более 100 языков, включая языки программирования, обеспечивая надежные возможности многоязычного, межъязыкового и поиска кода.
- Модели встраивания позволяют гибко определять векторы и пользовательские инструкции для настройки производительности под конкретные задачи или языки.
-
Производительность и сценарии использования
- Передовые результаты в задачах извлечения текста, извлечения кода, классификации, кластеризации и извлечения параллельных текстов.
- Модели повторного ранжирования превосходны в различных сценариях извлечения текста и могут быть легко объединены с моделями встраивания для конвейеров извлечения end-to-end.
Как использовать на Ollama
Вы можете запустить эти модели на Ollama с помощью команд, таких как:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Выберите версию квантования, которая лучше всего подходит для ваших аппаратных и производительных потребностей.
Таблица сводки
| Тип модели | Доступные размеры | Основные сильные стороны | Поддержка нескольких языков | Опции квантования |
|---|---|---|---|---|
| Встраивание | 0.6B, 4B, 8B | Топовые результаты MTEB, гибкость, эффективность, SOTA | Да (более 100 языков) | Q4, Q5, Q6, Q8 и т.д. |
| Повторное ранжирование | 0.6B, 4B, 8B | Превосходно в оценке релевантности пар текста, эффективность, гибкость | Да | F16, Q4, Q5 и т.д. |
Великолепные новости!
Модели Qwen3 Embedding и Reranker на Ollama представляют собой значительный прорыв в области многоязычного и многофункционального извлечения текста и кода. Благодаря гибким вариантам развертывания, сильной производительности на тестах и поддержке широкого круга языков и задач, они отлично подходят как для исследовательских, так и для промышленных сред.
Зоопарк моделей - удовольствие для глаз теперь
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
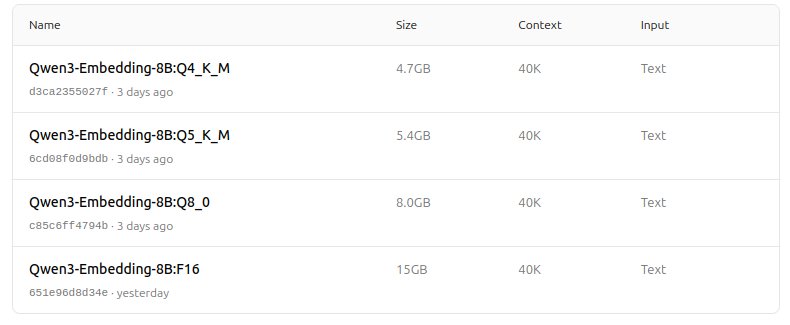
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
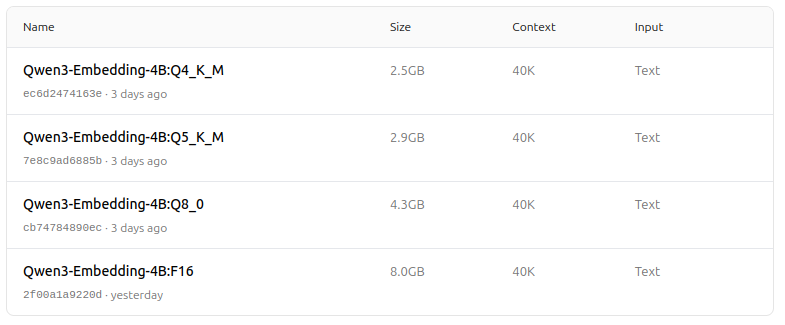
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
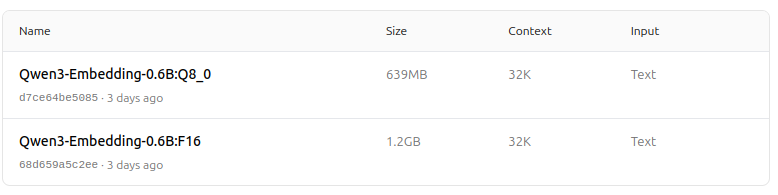
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
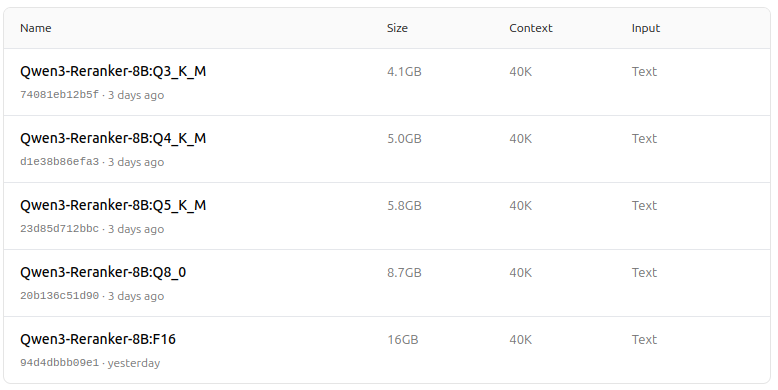
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
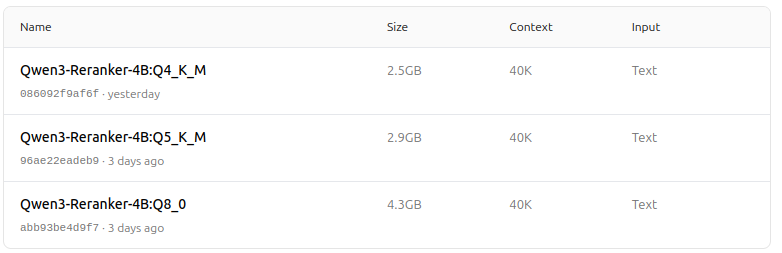
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
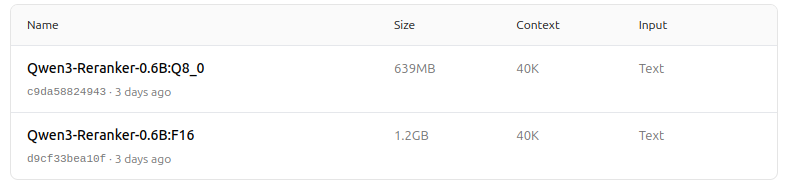
Хорошо!
Полезные ссылки
- Повторное ранжирование текстовых документов с использованием Ollama и модели Qwen3 Embedding - на Go
- Повторное ранжирование текстовых документов с использованием Ollama и модели Qwen3 Reranker - на Go
- Ollama cheatsheet
- Перемещение моделей Ollama на другой диск или папку
- Самохостинг Perplexica с использованием Ollama
- Тест: Как Ollama использует производительность и эффективные ядра процессора Intel
- Сравнение скорости работы LLM
- Сравнение способностей LLM к суммированию
- Облачные поставщики LLM
- Как Ollama обрабатывает параллельные запросы
- Сравнение качества перевода страниц Hugo - LLMs на Ollama
