
Modele Qwen3 Embedding i Reranker na Ollama: osiągnięcia stanowiące stan techniki
Nowe, imponujące modele LLM dostępne w Ollama
Modele Qwen3 Embedding i Reranker (https://www.glukhov.org/pl/rag/embeddings/qwen3-embedding-qwen3-reranker-on-ollama/ “Modele Qwen3 Embedding i Reranker na platformie ollama”) to najnowsze wydania z rodziny Qwen, zaprojektowane specjalnie do zaawansowanych zadań związanych z tworzeniem wektorów tekstu (embedding), odnajdywaniem informacji (retrieval) oraz ponownym ocenianiem wyników (reranking).
Radość dla oczu
Modele Qwen3 Embedding i Reranker stanowią znaczący postęp w wielojęzycznym przetwarzaniu języka naturalnego (NLP), oferując osiągi klasy światowej (SOTA) w zadaniach związanych z generowaniem wektorów i ponownym ocenianiem tekstu. Te modele, będące częścią serii Qwen opracowanej przez firmę Alibaba, zostały zaprojektowane tak, aby wspierać szeroki zakres zastosowań – od wyszukiwania semantycznego po przeszukiwanie kodu. Tego typu możliwości generowania wektorów są fundamentem budowania skutecznych systemów RAG (Retrieval-Augmented Generation), o czym szczegółowo opowiedziano w Poradniku RAG: Architektura, Implementacja i Przewodnik Produkcyjny. Chociaż Ollama jest popularną platformą open source do hostowania i wdrażania dużych modeli językowych (LLM), integracja modeli Qwen3 z Ollama nie jest wprost opisana w oficjalnej dokumentacji. Modele są jednak dostępne na Hugging Face, GitHubie oraz ModelScope, co umożliwia potencjalne wdrożenie lokalne poprzez Ollamę lub podobne narzędzia.
Przykłady użycia tych modeli
Oto przykładowy kod w języku Go wykorzystujący Ollamę z tymi modelami:
- Ponowne ocenianie dokumentów tekstowych z Ollamą i modelem Qwen3 Embedding - w języku Go
- Ponowne ocenianie dokumentów tekstowych z Ollamą i modelem Qwen3 Reranker - w języku Go
Przegląd nowych modeli Qwen3 Embedding i Reranker na Ollamie
Te modele są teraz dostępne do wdrożenia na platformie Ollama w różnych rozmiarach, zapewniając osiągi klasy światowej i elastyczność dla szerokiego spektrum aplikacji językowych i programistycznych.
Kluczowe funkcje i możliwości
-
Rozmiary modeli i elastyczność
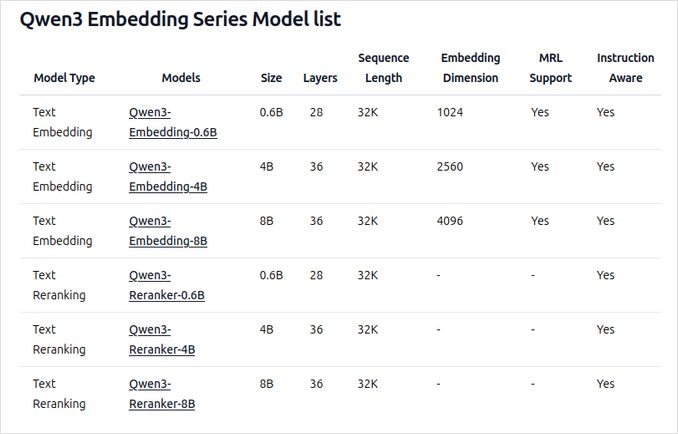
- Dostępne w wielkościach: 0.6B, 4B i 8B parametrów dla zadań embeddingu i rerankingu.
- Model embedding 8B aktualnie plasuje się na 1. miejscu na wielojęzycznym leaderboardze MTEB (stan na 5 czerwca 2025 r., z wynikiem 70.58).
- Obsługuje różne opcje kwantyzacji (Q4, Q5, Q8 itp.) dla zrównoważenia wydajności, zużycia pamięci i szybkości. Opcja Q5_K_M jest zalecana dla większości użytkowników, ponieważ zachowuje większość wydajności modelu, pozostając oszczędna pod względem zasobów.
-
Architektura i trening
- Zbudowane na fundamencie Qwen3, wykorzystujące zarówno architekturę podwójnego enkodera (dla embeddingów), jak i enkodera krzyżowego (dla rerankingu).
- Model embedding: Przetwarza pojedyncze segmenty tekstu, wydobywając reprezentacje semantyczne z końcowego stanu ukrytego.
- Model reranker: Przyjmuje pary tekstów (np. zapytanie i dokument) i zwraca wynik istotności, stosując podejście cross-encoder.
- Modele embedding stosują trzyetapową paradygmat treningowy: kontrastowe predrenowanie, nadzorowany trening z wykorzystaniem danych wysokiej jakości oraz scalanie modeli dla optymalnej generalizacji i adaptowalności.
- Modele reranker są trenowane bezpośrednio z wykorzystaniem danych znakowanych wysokiej jakości dla efektywności i skuteczności.
-
Wsparcie wielojęzyczne i wielozadaniowe
- Obsługuje ponad 100 języków, w tym języki programowania, umożliwiając solidne możliwości wyszukiwania wielojęzycznego, międzyjęzycznego oraz kodu.
- Modele embedding pozwalają na elastyczne definicje wektorów i instrukcje definiowane przez użytkownika, aby dostosować wydajność do konkretnych zadań lub języków.
- Dla aplikacji wymagających możliwości multimodalnych wykraczających poza tekst, zobacz Embeddingi międzymodalne: Łączenie modalności AI.
-
Wydajność i przypadki użycia
- Wyniki klasy światowej w wyszukiwaniu tekstu, kodu, klasyfikacji, grupowaniu (clustering) oraz kopalni bitextów.
- Modele reranker wyróżniają się w różnych scenariuszach wyszukiwania tekstu i mogą być bezproblemowo łączone z modelami embedding dla end-to-end pipeline’ów wyszukiwania.
Jak używać na Ollamie
Możesz uruchomić te modele na Ollamie przy użyciu komend takich jak:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Wybierz wersję kwantyzacji, która najlepiej odpowiada Twojemu sprzętowi i potrzebom wydajnościowym.
Aktualizacja grudzień 2025: Ollama dostarcza teraz standardowe modele Qwen3 embedding ze swojego własnego repozytorium, a nie z repo dengcao:
ollama pull qwen3-embedding:8b
ollama pull qwen3-embedding:4b
Więcej informacji: https://ollama.com/library/qwen3-embedding
Tabela podsumowująca
| Typ modelu | Dostępne rozmiary | Kluczowe mocne strony | Obsługa języków | Opcje kwantyzacji |
|---|---|---|---|---|
| Embedding | 0.6B, 4B, 8B | Najwyższe wyniki MTEB, elastyczne, wydajne, SOTA | Tak (100+ języków) | Q4, Q5, Q6, Q8, itd. |
| Reranker | 0.6B, 4B, 8B | Wyróżnia się oceną istotności par tekstowych, wydajne, elastyczne | Tak | F16, Q4, Q5, itd. |
Świetne wiadomości!
Modele Qwen3 Embedding i Reranker na Ollamie stanowią znaczący krok naprzód w możliwościach wyszukiwania tekstu i kodu w wielu językach i wielu zadaniach. Dzięki elastycznym opcjom wdrażania, silnej wydajności w benchmarkach oraz obsłudze szerokiego spektrum języków i zadań, są one idealnie dopasowane zarówno do środowisk badawczych, jak i produkcyjnych.
Zoo modeli - teraz radość dla oczu
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
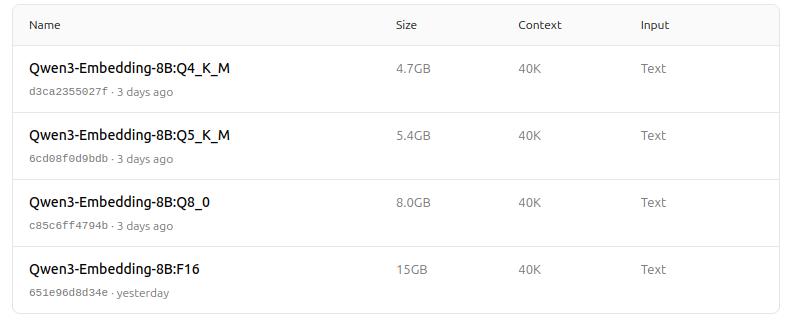
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
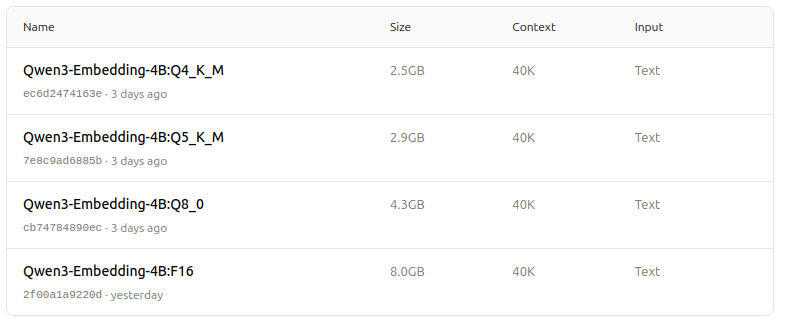
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
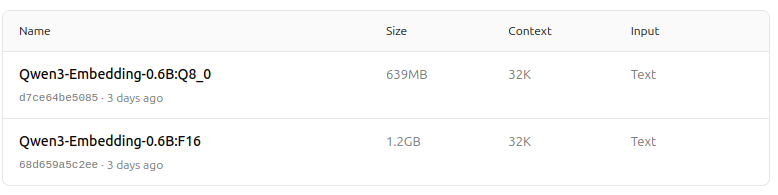
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
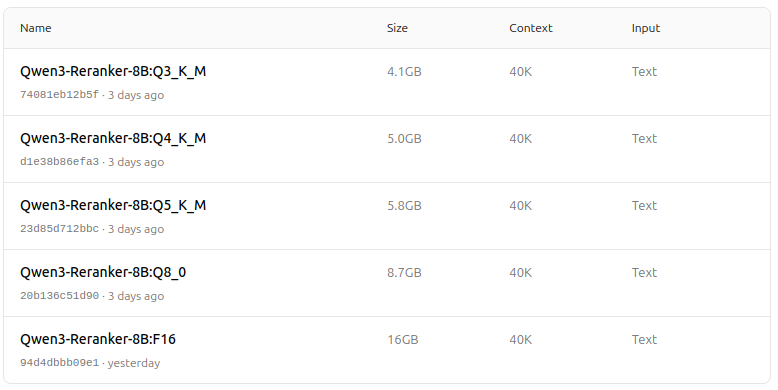
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
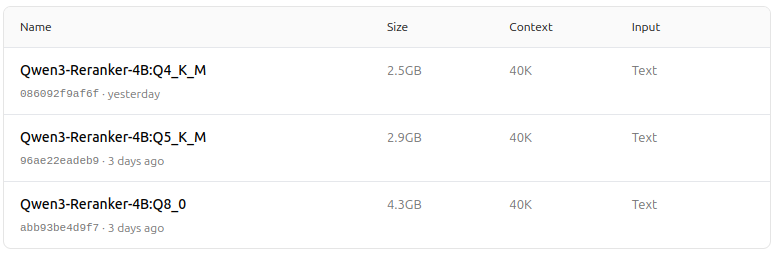
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
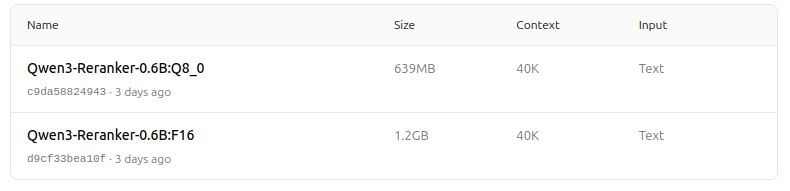
Świetnie!
Przydatne linki
- Ponowne ocenianie dokumentów tekstowych z Ollamą i modelem Qwen3 Embedding - w języku Go
- Ponowne ocenianie dokumentów tekstowych z Ollamą i modelem Qwen3 Reranker - w języku Go
- Cheat sheet Ollama
- Przenoszenie modeli Ollama na inny dysk lub do innego folderu
- Self-hosting Perplexica - z Ollamą
- Test: Jak Ollama wykorzystuje wydajność procesora Intel i rdzenie Efficient
- Porównanie szybkości LLM
- Porównanie zdolności do podsumowywania LLM
- Dostawcy chmurowi LLM
- Jak Ollama obsługuje równoległe żądania
- Porównanie jakości tłumaczenia stron Hugo - LLM na Ollamie
