
Modelli di Embedding e Reranker Qwen3 su Ollama: prestazioni all'avanguardia
Nuovi e potenti LLM disponibili su Ollama
I modelli Qwen3 Embedding e Reranker sono le ultime uscite della famiglia Qwen, progettati specificamente per compiti avanzati di incorporazione (embedding), recupero (retrieval) e riordinamento (reranking) del testo.
Gioia per gli occhi
I modelli Qwen3 Embedding e Reranker rappresentano un significativo avanzamento nell’elaborazione del linguaggio naturale (NLP) multilingue, offrendo prestazioni all’avanguardia nei compiti di embedding e reranking. Questi modelli, parte della serie Qwen sviluppata da Alibaba, sono progettati per supportare un’ampia gamma di applicazioni, dal recupero semantico alla ricerca nel codice. Questo tipo di capacità di embedding è fondamentale per costruire sistemi RAG efficaci, come descritto in dettaglio nel Tutorial sulla Generazione Aumentata dal Recupero (RAG): Architettura, Implementazione e Guida alla Produzione. Sebbene Ollama sia una piattaforma open-source popolare per l’hosting e il deployment di grandi modelli linguistici (LLM), l’integrazione dei modelli Qwen3 con Ollama non è esplicitamente dettagliata nella documentazione ufficiale. Tuttavia, i modelli sono accessibili tramite Hugging Face, GitHub e ModelScope, consentendo un potenziale deployment locale tramite Ollama o strumenti simili.
Esempi di utilizzo di questi modelli
Si prega di consultare il codice di esempio in Go che utilizza ollama con questi modelli:
- Reranking di documenti testuali con Ollama e il modello Qwen3 Embedding - in Go
- Reranking di documenti testuali con Ollama e il modello Qwen3 Reranker - in Go
Panoramica dei nuovi modelli Qwen3 Embedding e Reranker su Ollama
Questi modelli sono ora disponibili per il deployment su Ollama in varie dimensioni, offrendo prestazioni all’avanguardia e flessibilità per un’ampia gamma di applicazioni relative a linguaggio e codice.
Caratteristiche e capacità principali
-
Dimensioni del modello e flessibilità
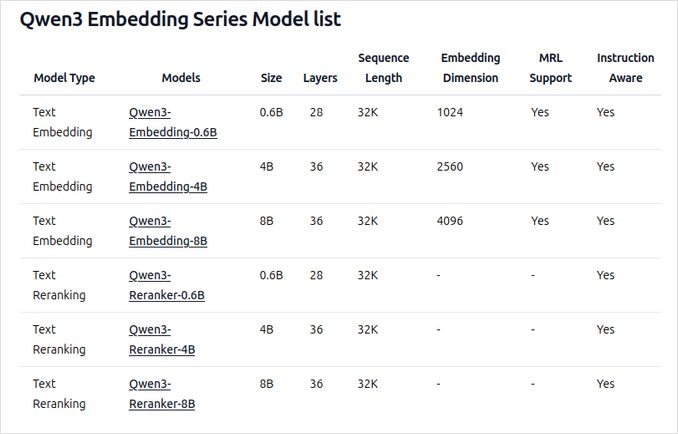
- Disponibili in più dimensioni: 0.6B, 4B e 8B parametri per entrambi i compiti di embedding e reranking.
- Il modello embedding da 8B attualmente si posiziona al No. 1 nella classifica multilingue MTEB (al 5 giugno 2025, con un punteggio di 70.58).
- Supporta una gamma di opzioni di quantizzazione (Q4, Q5, Q8, ecc.) per bilanciare prestazioni, utilizzo della memoria e velocità. Q5_K_M è consigliato per la maggior parte degli utenti in quanto preserva la maggior parte delle prestazioni del modello pur essendo efficiente nelle risorse.
-
Architettura e addestramento
- Costruiti sulla base di Qwen3, sfruttando sia l’architettura dual-encoder (per gli embedding) che cross-encoder (per il reranking).
- Modello Embedding: elabora singoli segmenti di testo, estraendo rappresentazioni semantiche dallo stato nascosto finale.
- Modello Reranker: prende coppie di testo (ad esempio, query e documento) e restituisce un punteggio di rilevanza utilizzando un approccio cross-encoder.
- I modelli Embedding utilizzano un paradigma di addestramento a tre stadi: pre-addestramento contrastivo, addestramento supervisionato con dati di alta qualità e fusione di modelli per una generalizzazione e adattabilità ottimali.
- I modelli Reranker sono addestrati direttamente con dati etichettati di alta qualità per efficienza ed efficacia.
-
Supporto multilingue e multitask
- Supporta oltre 100 lingue, inclusi i linguaggi di programmazione, abilitando robuste capacità di recupero multilingue, cross-linguistico e del codice.
- I modelli Embedding consentono definizioni vettoriali flessibili e istruzioni definite dall’utente per adattare le prestazioni a compiti o lingue specifici.
- Per applicazioni che richiedono capacità multimodali oltre al testo, vedi Embeddings Cross-Modal: Colmare il divario tra le modalità AI.
-
Prestazioni e casi d’uso
- Risultati all’avanguardia nel recupero di testo, recupero di codice, classificazione, clustering e mining di bitext.
- I modelli Reranker eccellono in vari scenari di recupero di testo e possono essere combinati senza soluzione di continuità con i modelli embedding per pipeline di recupero end-to-end.
Come utilizzare su Ollama
È possibile eseguire questi modelli su Ollama con comandi come:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Scegli la versione di quantizzazione che meglio si adatta alle tue esigenze di hardware e prestazioni.
Aggiornamento dicembre 2025: Ora Ollama fornisce modelli di embedding Qwen3 standard, dal proprio repository, non da quello di dengcao:
ollama pull qwen3-embedding:8b
ollama pull qwen3-embedding:4b
Vedi altro: https://ollama.com/library/qwen3-embedding
Tabella riassuntiva
| Tipo di Modello | Dimensioni disponibili | Punti di forza principali | Supporto multilingue | Opzioni di quantizzazione |
|---|---|---|---|---|
| Embedding | 0.6B, 4B, 8B | Punteggi MTEB in testa, flessibile, efficiente, SOTA | Sì (100+ lingue) | Q4, Q5, Q6, Q8, ecc. |
| Reranker | 0.6B, 4B, 8B | Eccelle nella rilevanza delle coppie di testo, efficiente, flessibile | Sì | F16, Q4, Q5, ecc. |
Notizie fantastiche!
I modelli Qwen3 Embedding e Reranker su Ollama rappresentano un salto significativo nelle capacità di recupero di testo e codice multilingue e multitask. Con opzioni di deployment flessibili, forti prestazioni nei benchmark e supporto per un’ampia gamma di lingue e compiti, sono ideali sia per ambienti di ricerca che per la produzione.
Zoo dei modelli - piacere per gli occhi ora
Qwen3 Embedding
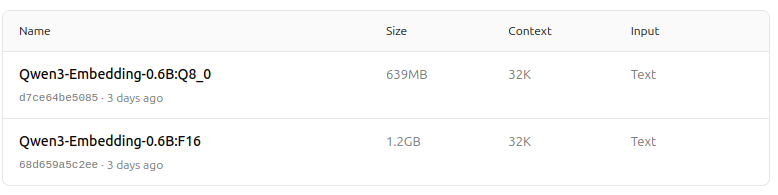
https://ollama.com/dengcao/Qwen3-Embedding-8B
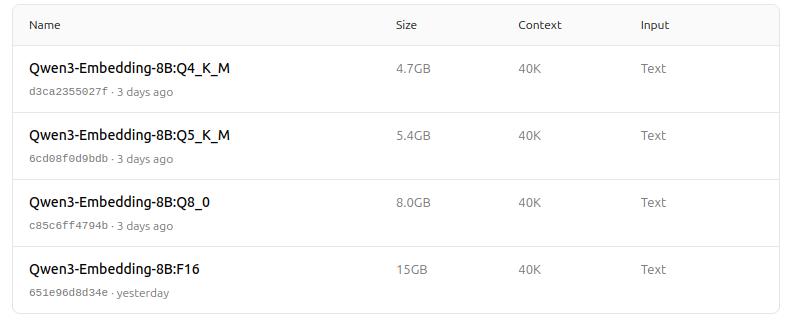
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
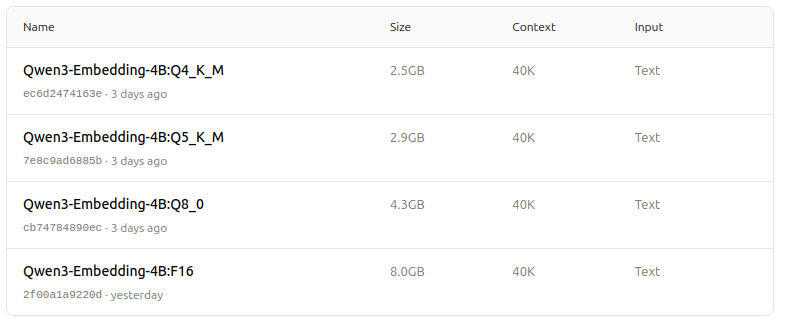
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
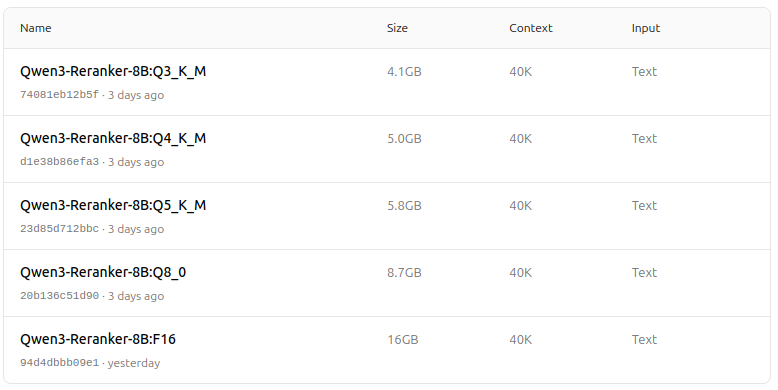
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
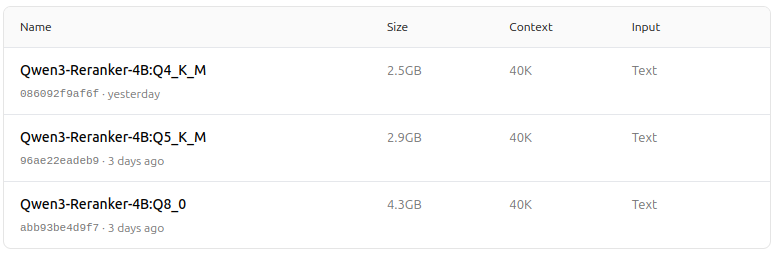
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
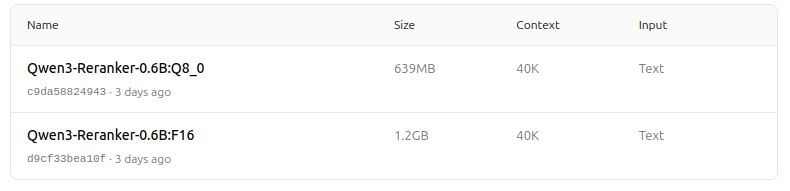
Bellissimo!
Link utili
- Reranking di documenti testuali con Ollama e il modello Qwen3 Embedding - in Go
- Reranking di documenti testuali con Ollama e il modello Qwen3 Reranker - in Go
- Ollama cheatsheet
- Spostare i modelli Ollama in un’unità o cartella diversa
- Self-hosting di Perplexica - con Ollama
- Test: Come Ollama utilizza le prestazioni della CPU Intel e i core efficienti
- Confronto delle prestazioni di velocità degli LLM
- Confronto delle capacità di sintesi degli LLM
- Provider di LLM Cloud
- Come Ollama gestisce le richieste parallele
- Confronto sulla qualità della traduzione delle pagine Hugo - LLM su Ollama
