

Comparaison des assistants de codage par IA
Cursor IA contre GitHub Copilot contre Cline IA...
Voici une liste d’outils d’assistance au codage basés sur l’intelligence artificielle (IA) et leurs avantages.
Cursor IA contre GitHub Copilot contre Cline IA...
Voici une liste d’outils d’assistance au codage basés sur l’intelligence artificielle (IA) et leurs avantages.

Ollama sur processeur Intel : cœurs d'efficacité vs cœurs de performance
J’ai une théorie à tester - si l’utilisation de tous les cœurs d’un processeur Intel augmenterait la vitesse des LLM ? Cela me tracasse que le nouveau modèle gemma3 27 bit (gemma3:27b, 17 Go sur ollama) ne tienne pas dans les 16 Go de VRAM de mon GPU, et qu’il s’exécute partiellement sur le CPU.

Configurer ollama pour l'exécution de requêtes en parallèle.
Lorsque le serveur Ollama reçoit deux demandes en même temps, son comportement dépend de sa configuration et des ressources système disponibles.

« Comparaison de deux modèles deepseek-r1 avec deux modèles de base »
DeepSeek’s première génération de modèles de raisonnement avec des performances comparables à celles d’OpenAI-o1, incluant six modèles denses distillés à partir de DeepSeek-R1 basés sur Llama et Qwen.

Liste mise à jour des commandes Ollama - ls, ps, run, serve, etc.
Ce Ollama CLI cheatsheet se concentre sur les commandes que vous utilisez tous les jours (ollama ls, ollama serve, ollama run, ollama ps, gestion des modèles et flux de travail courants), avec des exemples que vous pouvez copier/coller.

Prochaine série de tests LLM
Il y a peu de temps, a été publié. Commençons par un point sur la mise à jour et testons comment Mistral Small se compare aux autres LLMs ici.

Un code Python pour le reranking de RAG

Comparaison de deux moteurs de recherche d'IA auto-hébergés
La bonne nourriture est aussi un plaisir pour les yeux. Mais dans cet article, nous allons comparer deux systèmes de recherche basés sur l’IA, Farfalle et Perplexica.
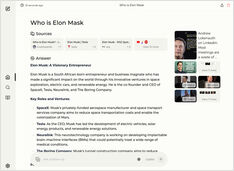
Exécuter un service du style Copilot localement ? Facile !
C’est très excitant !
Au lieu d’appeler Copilot ou Perplexity.ai et de tout raconter au monde, vous pouvez maintenant héberger un service similaire sur votre propre ordinateur ou laptop !
Pas tant d'options à choisir, mais tout de même...
Quand j’ai commencé à expérimenter avec les LLM, les interfaces utilisateur pour eux étaient en développement actif, et maintenant certaines d’entre elles sont vraiment excellentes.

Test de détection des fautes de raisonnement
Récemment, nous avons vu plusieurs nouveaux LLM sortir. Des temps excitants. Testons-les et voyons comment ils se débrouillent lorsqu’ils détectent les fautes logiques.

Exige quelques expérimentations mais
Il existe toutefois quelques approches courantes pour rédiger des prompts efficaces afin que le modèle de langage ne se confonde pas en tentant de comprendre ce que vous souhaitez.

« 8 versions de llama3 (Meta+) et 5 versions de phi3 (Microsoft) »
Testons comment les modèles avec différents nombres de paramètres et de quantification se comportent.

Les fichiers de modèles LLM d'Ollama prennent beaucoup de place.
Après avoir installé ollama, il est préférable de reconfigurer ollama pour qu’ils soient stockés dans un nouvel emplacement dès maintenant. Ainsi, après avoir tiré un nouveau modèle, il ne sera pas téléchargé vers l’ancien emplacement.