Zaawansowane reprezentacje przekrojowe: łączenie trybów AI
Zjednocz tekst, obrazy i dźwięk w współdzielonych przestrzeniach osadzeń.
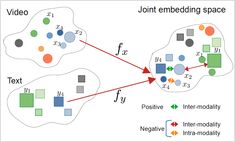
Przestrzenne reprezentacje przekrojowe stanowią przełom w sztucznej inteligencji, umożliwiając zrozumienie i rozumowanie na przekrój danych w jednolitej przestrzeni reprezentacji.