
Guardrails para LLMs en la práctica: qué funciona realmente
Controla el riesgo, no solo el modelo.
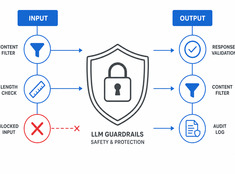
Los modelos de lenguaje grande (LLM) son impredecibles. Alucinan, filtran datos, generan contenido dañino o rechazan solicitudes legítimas. Los mecanismos de protección (guardrails) restringen el comportamiento del modelo sin sacrificar su capacidad.