
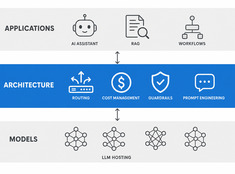
Arquitectura de LLM: Diseño de sistemas para IA en producción
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
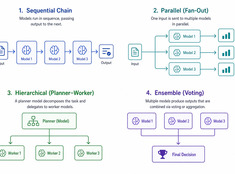
Elija el patrón más simple que funcione.
Los sistemas de un solo modelo son simples. Los sistemas de múltiples modelos son potentes. El desafío no consiste en elegir modelos, sino en diseñar la arquitectura que los orqueste.
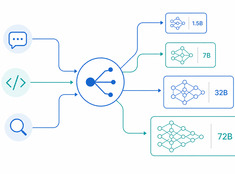
«El modelo adecuado para la tarea adecuada».
Ejecutar un modelo de 70 mil millones de parámetros para resumir un correo electrónico de 200 palabras es un desperdicio. Ejecutar un modelo de 3 mil millones de parámetros para revisar código en producción es imprudente. La mayoría de los sistemas se encuentran en algún punto intermedio, y ahí es donde entra la enrutación de modelos.
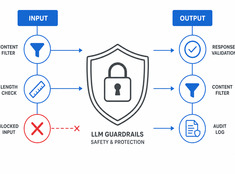
Controla el riesgo, no solo el modelo.
Los modelos de lenguaje grande (LLM) son impredecibles. Alucinan, filtran datos, generan contenido dañino o rechazan solicitudes legítimas. Los mecanismos de protección (guardrails) restringen el comportamiento del modelo sin sacrificar su capacidad.
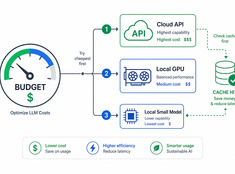
Gasta tokens donde realmente importan.
Los costos de los LLM escalan de forma lineal con el uso. Un sistema que procesa 10.000 solicitudes al día a $0,01 por solicitud cuesta $100 diarios — $365 al año. A escala empresarial, eso supera los $10.000.

Memoria de trabajo, estructurada y de recuperación para asistentes.
La memoria transforma a los asistentes de reactivos a persistentes, pero también es donde muchos sistemas se deterioran silenciosamente. Las encuestas argumentan que la división entre memoria a corto y largo plazo ya no es suficiente para la memoria de los agentes modernos; los SDK de OpenAI y LangGraph apuntan a una arquitectura más simple: memoria de trabajo, estado duradero y recuperación.

Cómo se construyen realmente los asistentes de IA.
Un asistente de IA en producción no es “un LLM con un prompt”. Es un sistema que acepta la intención del usuario, mantiene el estado, decide cuándo recuperar información o actuar, y expone suficiente detalle en tiempo de ejecución para depurar fallos.

La IA transforma la gestión del conocimiento, no su propósito.
La IA no está reemplazando la gestión del conocimiento; está cambiando su forma tanto para individuos como para equipos.
Estrellas, tokens, descargas: ¿quién gana realmente?
Los frameworks de agentes de IA de código abierto están experimentando un aumento explosivo en popularidad en GitHub. Dos proyectos en el centro del ecosistema de sistemas de IA autoalojados — OpenClaw y Hermes Agent — han avanzado tanto que el resto del campo lucha por un distante tercer lugar.

MTP frente a la decodificación estándar en RTX 4080: benchmarks reales
Probé el rendimiento de la decodificación especulativa (Predicción Multitoken, MTP) en Qwen 3.6 27B y 35B en una RTX 4080 con 16 GB de VRAM.

VRAM libre sin detener llama-server.
Modo router de llama.cpp es uno de los cambios más útiles en llama-server en años. Finalmente ofrece a los operadores de LLM locales una experiencia de gestión de modelos cercana a la que las personas esperan de Ollama, manteniendo al mismo tiempo el rendimiento bruto y el control a bajo nivel que hacen que llama.cpp valga la pena usarlo en primer lugar.

Conocimiento compilado para sistemas de IA
La premisa es simple: el conocimiento compilado es más reutilizable que los fragmentos recuperados. RAG se convirtió en la respuesta predeterminada a una pregunta directa: ¿cómo proporciono a un LLM acceso a conocimiento externo?

Deja de interpretar sensaciones. Valida contratos.
La mayoría de los tutoriales sobre “salida estructurada” de los LLM son poco serios. Te enseñan a pedir JSON amablemente y luego a esperar que el modelo se comporte. Eso no es validación. Eso es optimismo con llaves.

Referencia de ajuste de LLMs agénticos
Esta página es una referencia práctica para la afinación de inferencia de LLMs agentivos (temperatura, top_p, top_k, penalizaciones y cómo interactúan en flujos de trabajo multietapa y con uso intensivo de herramientas).

Habla con Hermes desde tu teléfono
Ya puedes chatear con Hermes Agent desde tu teléfono usando texto. Ahora quieres hablar con él directamente y recibir respuestas habladas. Eso suele ser la mejor opción, especialmente si ya usas Hermes como asistente autohospedado persistente. Escribir instrucciones largas en una pantalla pequeña es lento y propenso a errores.

Controla la carga de Hermes Kanban en tu LLM autohospedado.
El agente Hermes incluye un tablero estilo Kanban y el Hermes Gateway, que pueden saturar su LLM autoalojado si se asignan demasiadas tareas a la vez.