
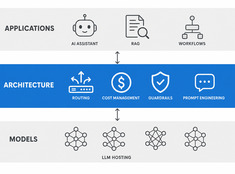
LLM-arkitektur: Systemdesign för produktionsberedd AI
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
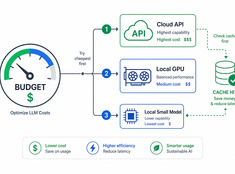
Använd token där de verkligen spelar roll.
Kostnader för stora språkmodeller (LLM) ökar linjärt med användningen. Ett system som bearbetar 10 000 förfrågningar per dag till $0,01 per förfrågan kostar $100 dagligen – vilket innebär $365 per år. I enterprise-skala blir det mer än $10 000.
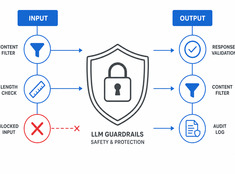
Kontrollera risken, inte bara modellen.
LLM:er är oförutsägbara. De hallucinerar, läcker data, genererar skadligt innehåll eller vägrar legitima begäran. Skyddsnät begränsar modellens beteende utan att offra kapacitet.
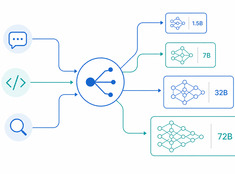
Rätt modell för rätt uppgift.
Att köra en modell med 70 miljarder parametrar för att sammanfatta ett 200-ord långt e-postmeddelande är slöseri. Att köra en 3-miljarders modell för att granskas produktionskod är slarvigt. De flesta system hamnar någonstans emellan — och det är här modellruttning kommer in i bilden.
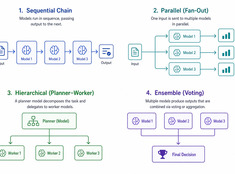
Välj det enklaste mönster som fungerar.
Enkelmodellsystem är enkla. Multimodellsystem är kraftfulla. Utmaningen ligger inte i att välja modeller, utan i att designa arkitekturen som dirigerar dem.

Arbets-, strukturerat och hämtat minne för assistenter.
Minne förvandlar assistenter från reaktiva till bestående, men det är också där många system tyst förfaller. Undersökningar hävdar att uppdelningen mellan kort- och långtidsminne inte längre räcker för modern agentminne; OpenAI och LangGraph SDK:er pekar på en enklare stack — arbetsminne, bestående tillstånd och hämtning.

Så allvarliga assistenter faktiskt byggs.
En produktionsklar AI-assistent är inte “en LLM med en prompt”. Det är ett system som tar emot avsikt, behåller tillstånd, beslutar när det ska hämta information eller utföra åtgärder, och exponerar tillräckligt med detaljer om körningen för att kunna felsöka fel.

AI förändrar kunskaps hanteringen, inte dess syfte.
AI ersätter inte kunskapsstyrning; den förändrar dess form för både individer och team.
Stjärnor, tokens, nedladdningar – vinner verkligen någon?
Open-source-ram för AI-agenter exploderar i popularitet på GitHub. Två projekt som ligger i kärnan av ekosystemet för självhushållande AI-system — OpenClaw och Hermes Agent — har dragit så långt ifrån att resten av fältet slåss om en fjärran tredjeplats.

MTP jämfört med standarddekodning på RTX 4080 — verkliga benchmarkresultat
Jag testade prestandan för spekulativ dekodning (Multi-Token Prediction, MTP) i Qwen 3.6 27B och 35B på en RTX 4080 med 16 GB VRAM.

Frigör VRAM utan att stoppa llama-server.
Routerläge för llama.cpp är en av de mest användbara förändringarna i llama-server på flera år. Det ger slutligen lokala aktörer av LLM (Large Language Models) något som liknar modellhanteringsupplevelsen som man förväntar sig från Ollama, samtidigt som det behåller den råa prestanda och den lågnivåkontroll som gör llama.cpp värd att använda i första hand.

Sammanställd kunskap för AI-system
Premissen är enkel: sammanställd kunskap är mer återanvändbar än hämtade fragment. RAG blev det självklara svaret på en enkel fråga – hur ger jag en LLM (storspråkmodell) tillgång till extern kunskap?

En karta över moderna kunskapssystem
PKM, RAG, wikis, AI-minnesystem och nu praktiska AI-assisterade arbetsflöden diskuteras ofta som om de löste samma problem. Det gör de inte. De hanterar alla kunskap, men de opererar på olika lager:

Sluta tolka stämningar. Validera kontrakt.
De flesta tutorials om “strukturerad utdata” från stora språkmodeller (LLM) är oseriösa. De lägger upp det som att du ska be artigt om JSON och sedan hoppas att modellen beter sig. Det är inte validering. Det är optimisme med klammermärken.

Referens för agensbaserad LLM-tuning
Denna sida är en praktisk referens för justering av agentic LLM-inferens (temperatur, top_p, top_k, strafftermer och hur de samverkar i flerstegs- och verktygstäta arbetsflöden).

Kontakta Hermes från din telefon
Du chattar redan med Hermes Agent från din telefon med text. Nu vill du prata med den direkt och få muntliga svar tillbaka. Det är oftast rätt val, särskilt om du redan använder Hermes som en självhostad assistent. Att skriva långa prompter på en liten skärm är långsamt och benäget för fel