

16GB VRAM GPU에서 Ollama를 사용한 LLM 성능 비교
RTX 4080(16GB VRAM)에서의 LLM 속도 테스트
로컬에서 대규모 언어 모델을 실행하면 개인 정보 보호, 오프라인 기능, API 비용 0원 등의 이점을 얻을 수 있습니다. 이 벤치마크는 RTX 4080에서 Ollama를 사용한 14개의 인기 있는 LLM의 성능을 정확하게 보여줍니다.
RTX 4080(16GB VRAM)에서의 LLM 속도 테스트
로컬에서 대규모 언어 모델을 실행하면 개인 정보 보호, 오프라인 기능, API 비용 0원 등의 이점을 얻을 수 있습니다. 이 벤치마크는 RTX 4080에서 Ollama를 사용한 14개의 인기 있는 LLM의 성능을 정확하게 보여줍니다.
자신의 Linux 워크플로에 적합한 터미널을 선택하세요
Linux 사용자에게 가장 중요한 도구 중 하나는 터미널 에뮬레이터입니다. https://www.glukhov.org/ko/developer-tools/terminals-shell/terminal-emulators-for-linux-comparison/ “Linux 터미널 에뮬레이터 비교”
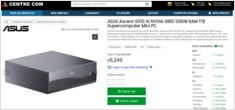
지금 호주 현지 소매업체의 실제 AUD 가격
NVIDIA DGX Spark (GB10 Grace Blackwell) 은 이제 주요 PC 판매점에서 재고 상태로 호주에서도 구매 가능 합니다. 전 세계 DGX Spark 가격과 가용성 을 지켜보셨다면, 호주의 가격은 저장 구성과 판매처에 따라 6,249 호주 달러에서 7,999 호주 달러 사이임을 알게 되시면 흥미로워하실 것입니다.

AI 에 적합한 소비자용 GPU 가격 – RTX 5080 과 RTX 5090
특히 LLM 과 일반적인 AI 에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 구체적으로는 RTX-5080 과 RTX-5090 가격 에 초점을 맞추고 있습니다.
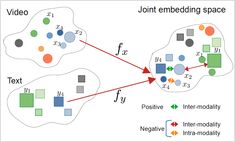
텍스트, 이미지 및 오디오를 공유된 임베딩 공간에 통합하세요.
크로스모달 임베딩은 인공지능 분야에서의 중요한 돌파구로, 다양한 데이터 유형을 하나의 통합된 표현 공간 내에서 이해하고 추론하는 것을 가능하게 합니다.

오픈 모델로 저비용 하드웨어에서 엔터프라이즈 AI 배포
AI 의 민주화는 이제 현실이 되었습니다. Llama, Mistral, Qwen 과 같은 오픈소스 LLM 이 독점 모델들과 경쟁할 수준에 도달함에 따라, 팀들은 소비자용 하드웨어를 활용한 AI 인프라 구축 을 통해 비용을 절감하면서도 데이터 프라이버시와 배포에 대한 완전한 통제를 유지할 수 있게 되었습니다.

Docker 모델 러너에서 컨텍스트 크기 구성 및 대안 마련
Docker 모델 러너에서 컨텍스트 크기 구성은 예상보다 더 복잡한 경우가 많습니다.

텍스트 지시문으로 이미지를 강화하는 AI 모델
블랙 포레스트 랩스는 텍스트 지시문을 사용하여 기존 이미지를 향상시키는 고급 이미지에서 이미지로 생성하는 AI 모델인 FLUX.1-Kontext-dev를 출시했습니다.

NVIDIA CUDA 지원을 통해 Docker 모델 실행기에서 GPU 가속을 활성화하세요.
Docker Model Runner은 AI 모델을 로컬에서 실행하는 Docker의 공식 도구이지만,
Docker Model Runner에서 NVidia GPU 가속 기능 활성화
은 특정 설정이 필요합니다.

GPT-OSS 120b의 세 AI 플랫폼에서의 벤치마크
저는 Ollama에서 실행되는 GPT-OSS 120b의 성능 테스트 결과를 NVIDIA DGX Spark, Mac Studio, RTX 4080 세 가지 플랫폼에서 확인해보았습니다. Ollama 라이브러리에서 제공하는 GPT-OSS 120b 모델의 크기는 65GB로, RTX 4080의 16GB VRAM에 맞지 않으며, 더 최근의 RTX 5080에도 맞지 않습니다.
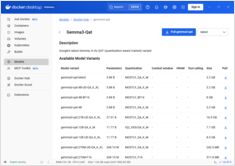
Docker Model Runner 명령어의 빠른 참조
Docker Model Runner (DMR)은 2025년 4월에 도입된 Docker의 공식 솔루션으로, 로컬에서 AI 모델을 실행하는 데 사용됩니다. 이 가이드는 모든 필수 명령, 구성 및 최선의 실천 방법을 위한 빠른 참조를 제공합니다.
로컬 LLM용 Docker Model Runner와 Ollama 비교
로컬에서 대규모 언어 모델(LLM) 실행 는 프라이버시, 비용 관리 및 오프라인 기능을 위해 점점 더 인기를 끌고 있습니다. 2025년 4월에 Docker가 Docker Model Runner (DMR), AI 모델 배포를 위한 공식 솔루션을 도입하면서 상황은 크게 변화했습니다.

6 개 국가의 가용성, 실제 소매 가격 및 Mac Studio 와의 비교.
NVIDIA DGX Spark 는 실존하며, 2025 년 10 월 15 일에 출시되어 통합 NVIDIA AI 스택을 갖춘 로컬 LLM 작업이 필요한 CUDA 개발자를 대상으로 합니다. 미국 권장 소매가 (MSRP) 는 3,999 달러이며, 영국/독일/일본의 소매가는 부가가치세 (VAT) 와 유통 채널 비용으로 인해 더 높습니다. 호주/한국의 공개 스티커 가격은 아직 널리 발표되지 않았습니다.

AI 에 적합한 소비자용 GPU 가격 - RTX 5080 과 RTX 5090
LLM 을 비롯한 AI 작업에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 특히 RTX-5080 과 RTX-5090 가격 에 주목합니다. 가격이 약간 하락했습니다.
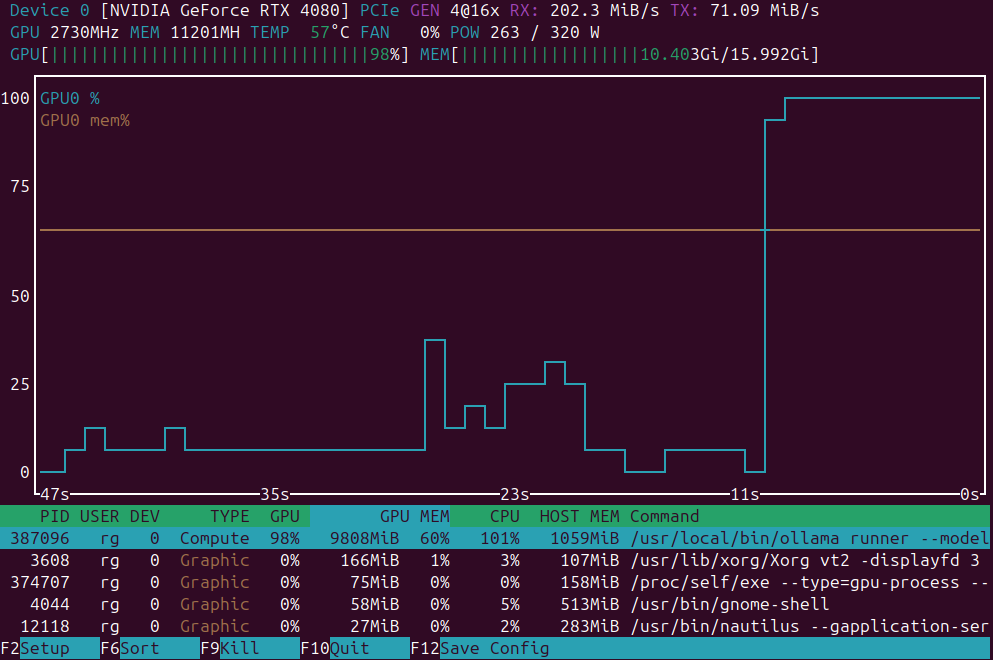
GPU 부하 모니터링을 위한 애플리케이션 목록
GPU 로드 모니터링 애플리케이션: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

2025 년 7 월이면 곧 이용 가능할 것입니다.
Nvidia 가 곧 NVIDIA DGX Spark를 출시합니다. 128GB 이상의 통합 RAM 과 1 PFLOPS AI 성능을 갖춘 블랙웰 (Blackwell) 아키텍처 기반의 소형 AI 슈퍼컴퓨터입니다. LLM 을 실행하기에 훌륭한 기기입니다.