

클라우드 LLM 제공업체
LLM 제공업체 짧은 목록
LLM을 사용하는 것은 매우 비용이 많이 들지 않으며, 새로운 고성능 GPU를 구매할 필요가 있을 수도 있습니다.
클라우드에서 제공하는 LLM 제공업체 목록을 확인해보세요. 이 목록에는 제공업체가 호스팅하는 LLM이 나와 있습니다.
LLM 제공업체 짧은 목록
LLM을 사용하는 것은 매우 비용이 많이 들지 않으며, 새로운 고성능 GPU를 구매할 필요가 있을 수도 있습니다.
클라우드에서 제공하는 LLM 제공업체 목록을 확인해보세요. 이 목록에는 제공업체가 호스팅하는 LLM이 나와 있습니다.

인텔 CPU의 효율성 코어 vs 성능 코어에서의 Ollama
제가 테스트하고 싶은 이론은, 인텔 CPU에서 모든 코어를 사용하면 LLM의 속도가 빨라질까?입니다.
새로운 gemma3 27비트 모델(gemma3:27b, ollama에서 17GB)이 제 GPU의 16GB VRAM에 맞지 않아, 부분적으로 CPU에서 실행되고 있다는 점이 제게 짜증을 주고 있습니다.

AI는 많은 컴퓨팅 파워가 필요합니다...
현대 세계의 혼란 속에서 저는 다른 카드의 기술 사양 비교를 진행하고 있습니다. 이는 AI 작업에 적합한 카드들입니다.
(딥러닝,
객체 감지,
LLMs).
하지만 이 모든 카드는 매우 비싸죠.

병렬 요청 실행을 위해 ollama 구성하기.
Ollama 서버가 동일한 시간에 두 개의 요청을 받을 경우, 그 동작은 구성 설정과 사용 가능한 시스템 자원에 따라 달라집니다.

타이핑이 아닌 설명으로 이루어지는 AI 지원 코딩
Vibe coding 은 개발자가 자연어로 원하는 기능을 설명하면 AI 도구가 코드를 자동으로 생성하는 AI 기반 프로그래밍 접근 방식입니다. 직접 코드를 작성하는 양은 최소화합니다.

두 개의 deepseek-r1 모델을 두 개의 기본 모델과 비교합니다.
DeepSeek’s 첫 세대 추론 모델로, OpenAI-o1과 유사한 성능을 보입니다. 이 모델은 Llama와 Qwen을 기반으로 한 DeepSeek-R1에서 추출한 6개의 밀집 모델입니다.

업데이트된 Ollama 명령어 목록 - ls, ps, run, serve 등
이 Ollama CLI 치트시트 는 매일 사용하는 명령어 (ollama ls, ollama serve, ollama run, ollama ps, 모델 관리 및 일반적인 워크플로우) 에 초점을 맞추며, 복사/붙여넣기 할 수 있는 예제를 제공합니다.

LLM 테스트 다음 라운드
지난 시간에 새로운 버전이 출시되었습니다. 지금까지의 내용을 확인하고, 기타 LLM과 비교하여 Mistral Small의 성능을 테스트해보세요.

RAG의 재순위화를 위한 Python 코드

놀랍도록 새로운 AI 모델로 텍스트에서 이미지 생성
최근 Black Forest Labs는 텍스트에서 이미지로 생성하는 AI 모델을 출시했습니다. 이 모델들은 매우 높은 출력 품질을 자랑한다고 알려져 있습니다. 시작해 보세요

두 개의 자체 호스팅 AI 검색 엔진 비교
아름다운 음식은 눈으로도 즐길 수 있는 즐거움입니다. 하지만 이번 포스팅에서는 두 가지 AI 기반 검색 시스템인 Farfalle 와 Perplexica 를 비교해 보겠습니다.
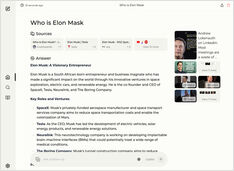
로컬에서 코파일럿 스타일 서비스를 실행하시나요? 간단합니다!
정말 흥미진진합니다!
코파일럿 (Copilot) 이나 perplexity.ai 에 접속하여 전 세계에 당신의 의도를 알릴 필요 없이, 이제 자신의 PC 나 노트북에서 유사한 서비스를 직접 호스팅할 수 있습니다!

논리적 오류 탐지 테스트
최근 몇몇 새로운 LLM이 출시되었습니다. 흥미로운 시기입니다. 논리적 오류를 감지하는 데 이 모델들이 어떻게 수행되는지 테스트해 보겠습니다.

일부 실험을 필요로 하지만
아직도 LLM이 당신이 원하는 것을 이해하려고 애를 쓰지 않도록 하기 위해 효과적인 프롬프트를 작성하는 데 사용되는 일반적인 접근 방법이 몇 가지 있습니다.

8개의 llama3 (Meta+) 및 5개의 phi3 (Microsoft) LLM 버전
다양한 파라미터 수와 양자화된 모델들이 어떻게 작동하는지 테스트해보았습니다.

Ollama LLM 모델 파일은 많은 공간을 차지합니다.
ollama 설치 후 모델을 즉시 새 위치로 저장하도록 ollama 를 재구성하는 것이 좋습니다. 이렇게 하면 새로운 모델을 풀링 (pull) 할 때 이전 위치로 다운로드되지 않습니다.