
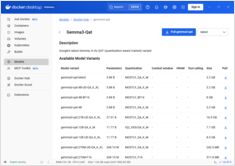
Docker Model Runner 참고 자료: 명령어 및 예제
Docker Model Runner 명령어의 빠른 참조
Docker Model Runner (DMR)은 2025년 4월에 도입된 Docker의 공식 솔루션으로, 로컬에서 AI 모델을 실행하는 데 사용됩니다. 이 가이드는 모든 필수 명령, 구성 및 최선의 실천 방법을 위한 빠른 참조를 제공합니다.
Docker Model Runner 명령어의 빠른 참조
Docker Model Runner (DMR)은 2025년 4월에 도입된 Docker의 공식 솔루션으로, 로컬에서 AI 모델을 실행하는 데 사용됩니다. 이 가이드는 모든 필수 명령, 구성 및 최선의 실천 방법을 위한 빠른 참조를 제공합니다.
로컬 LLM용 Docker Model Runner와 Ollama 비교
로컬에서 대규모 언어 모델(LLM) 실행 는 프라이버시, 비용 관리 및 오프라인 기능을 위해 점점 더 인기를 끌고 있습니다. 2025년 4월에 Docker가 Docker Model Runner (DMR), AI 모델 배포를 위한 공식 솔루션을 도입하면서 상황은 크게 변화했습니다.

전문적인 칩이 AI 추론을 더 빠르고 저렴하게 만들어가고 있습니다.

6 개 국가의 가용성, 실제 소매 가격 및 Mac Studio 와의 비교.
NVIDIA DGX Spark 는 실존하며, 2025 년 10 월 15 일에 출시되어 통합 NVIDIA AI 스택을 갖춘 로컬 LLM 작업이 필요한 CUDA 개발자를 대상으로 합니다. 미국 권장 소매가 (MSRP) 는 3,999 달러이며, 영국/독일/일본의 소매가는 부가가치세 (VAT) 와 유통 채널 비용으로 인해 더 높습니다. 호주/한국의 공개 스티커 가격은 아직 널리 발표되지 않았습니다.

이 두 모델의 속도, 파라미터 및 성능 비교
다음은 Qwen3:30b와 GPT-OSS:20b 사이의 비교입니다. 지시사항 준수 및 성능 파라미터, 사양 및 속도에 초점을 맞추고 있습니다.

+ 사고형 LLM을 사용한 구체적인 예시
이 포스트에서는 Python 애플리케이션을 Ollama에 연결하는 방법에 대해 두 가지 방법을 소개합니다: 1. HTTP REST API를 통해; 2. 공식 Ollama Python 라이브러리를 통해.

매우 좋지 않다.
Ollama의 GPT-OSS 모델은 특히 LangChain, OpenAI SDK, vllm과 같은 프레임워크와 함께 사용될 때 구조화된 출력을 처리하는 데 반복적으로 문제가 발생합니다.

조금 다른 API는 특별한 접근이 필요합니다.
다음은 구조화된 출력을 지원하는 주요 LLM 제공업체 간의 비교 및 최소한의 Python 예제입니다.

Ollama에서 구조화된 출력을 얻는 몇 가지 방법
대규모 언어 모델(LLMs) 은 강력하지만, 실제 운영 환경에서는 일반적인 문장이 아닌 예측 가능한 데이터를 원합니다. 즉, 앱에 입력할 수 있는 속성, 사실 또는 구조화된 객체를 원합니다. 이에 대해 LLM 구조화된 출력을 살펴보겠습니다.

내가 직접 수행한 ollama 모델 스케줄링 테스트
여기에서 저는 새로운 버전의 Ollama가 모델에 얼마나 많은 VRAM을 할당하는지와 이전 버전의 Ollama를 비교하고 있습니다. 새로운 버전은 오히려 더 나빠졌습니다.

현재 Ollama 개발 상태에 대한 제 의견
Ollama은 LLM을 로컬에서 실행하는 데 사용되는 가장 인기 있는 도구 중 하나로 빠르게 자리 잡았습니다. 간단한 CLI와 스트리밍된 모델 관리 기능으로 인해 클라우드 외부에서 AI 모델을 다루고자 하는 개발자들에게 필수적인 선택지가 되었습니다.
2025년 Ollama의 가장 주목받는 UI에 대한 간략한 개요
로컬에서 호스팅된 Ollama는 자신의 기계에서 대규모 언어 모델을 실행할 수 있게 해주지만, 명령줄을 통해 사용하는 것은 사용자 친화적이지 않습니다.
다음은 로컬 Ollama에 연결되는 **ChatGPT 스타일 인터페이스**를 제공하는 여러 오픈소스 프로젝트입니다.

2025 년 7 월이면 곧 이용 가능할 것입니다.
Nvidia 가 곧 NVIDIA DGX Spark를 출시합니다. 128GB 이상의 통합 RAM 과 1 PFLOPS AI 성능을 갖춘 블랙웰 (Blackwell) 아키텍처 기반의 소형 AI 슈퍼컴퓨터입니다. LLM 을 실행하기에 훌륭한 기기입니다.

MCP 사양과 GO에서의 구현에 대한 장문의 글
여기에는 **Model Context Protocol (MCP)**에 대한 설명과 Go로 작성된 MCP 서버를 구현하는 방법에 대한 간단한 노트, 메시지 구조 및 프로토콜 명세가 포함되어 있습니다.

RAG 구현 중이신가요? 여기 Go 코드 조각이 있습니다 - 2...
표준 Ollama 에는 직접적인 rerank API 가 없으므로, 쿼리 - 문서 쌍에 대한 임베딩을 생성하고 점수를 매기는 방식으로 GO 에서 Qwen3 Reranker 를 사용한 재순위 지정 을 구현해야 합니다.

qwen3 8b, 14b 및 30b, devstral 24b, mistral small 24b
이 테스트에서는 Ollama에 호스팅된 다양한 LLM이 Hugo 페이지를 영어에서 독일어로 번역하는 방식을 비교하고 있습니다. 다른 LLM이 호스팅된 Ollama에서 Hugo 페이지를 영어에서 독일어로 번역하는 방식 비교.