

파이썬에서 Ollama Web Search API 사용하기
파이썬과 올라마로 AI 검색 에이전트를 구축하세요.
Ollama의 Python 라이브러리는 이제 네이티브 OLlama 웹 검색 기능을 포함하고 있습니다. 몇 줄의 코드만으로도, 실시간 인터넷 정보를 사용하여 로컬 LLM을 보완할 수 있고, 환각을 줄이고 정확도를 향상시킬 수 있습니다.
파이썬과 올라마로 AI 검색 에이전트를 구축하세요.
Ollama의 Python 라이브러리는 이제 네이티브 OLlama 웹 검색 기능을 포함하고 있습니다. 몇 줄의 코드만으로도, 실시간 인터넷 정보를 사용하여 로컬 LLM을 보완할 수 있고, 환각을 줄이고 정확도를 향상시킬 수 있습니다.

RAG 스택에 적합한 벡터 DB 를 선택하세요
올바른 벡터 저장소 를 선택하는 것은 RAG 애플리케이션의 성능, 비용 및 확장성을 결정짓는 핵심 요소입니다. 이 포괄적인 비교 자료는 2024-2025 년에 가장 인기 있는 옵션들을 다룹니다.

Go와 Ollama로 AI 검색 에이전트를 구축하세요
Ollama의 웹 검색 API는 로컬 LLM에 실시간 웹 정보를 추가할 수 있게 해줍니다. 이 가이드는 Go에서 웹 검색 기능 구현 방법을 보여줍니다. 간단한 API 호출부터 완전한 기능의 검색 에이전트까지.

2026년 최고의 로컬 LLM 호스팅 도구 비교. API 성숙도, 하드웨어 지원, 도구 호출 및 실제 사례 사용.
로컬에서 대규모 언어 모델(LLM)을 실행하는 것이 이제 개발자, 스타트업, 심지어 기업 팀에게도 실용적이 되었습니다.
하지만 Ollama, vLLM, LM Studio, LocalAI 또는 기타 도구 중에서 적절한 도구를 선택하는 것은 당신의 목표에 따라 달라집니다:

Go 마이크로서비스를 사용하여 견고한 AI/ML 파이프라인을 구축하세요.
AI 및 머신러닝 워크로드가 점점 복잡해지면서, 견고한 오케스트레이션 시스템의 필요성이 더욱 커졌습니다. Go의 간결성, 성능, 동시성은 ML 파이프라인의 오케스트레이션 레이어를 구축하는 데 이상적인 선택이 됩니다. 모델 자체가 파이썬으로 작성되어 있더라도 말이죠.
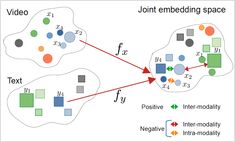
텍스트, 이미지 및 오디오를 공유된 임베딩 공간에 통합하세요.
크로스모달 임베딩은 인공지능 분야에서의 중요한 돌파구로, 다양한 데이터 유형을 하나의 통합된 표현 공간 내에서 이해하고 추론하는 것을 가능하게 합니다.

오픈 모델로 저비용 하드웨어에서 엔터프라이즈 AI 배포
AI 의 민주화는 이제 현실이 되었습니다. Llama, Mistral, Qwen 과 같은 오픈소스 LLM 이 독점 모델들과 경쟁할 수준에 도달함에 따라, 팀들은 소비자용 하드웨어를 활용한 AI 인프라 구축 을 통해 비용을 절감하면서도 데이터 프라이버시와 배포에 대한 완전한 통제를 유지할 수 있게 되었습니다.

LongRAG, Self-RAG, GraphRAG - 차세대 기법
검색 증강 생성 (RAG) 은 단순한 벡터 유사성 검색을 넘어 크게 진화했습니다. LongRAG, Self-RAG, GraphRAG 는 이러한 기능의 최전선을 대표합니다.

GGUF 양자화로 FLUX.1-dev 가속화
FLUX.1-dev 은 텍스트에서 이미지를 생성하는 강력한 모델로, 놀라운 결과를 제공하지만 24GB 이상의 메모리 요구 사항으로 인해 많은 시스템에서 실행하기 어렵습니다. GGUF quantization of FLUX.1-dev 은 메모리 사용량을 약 50% 줄이며 우수한 이미지 품질을 유지하는 해결책을 제공합니다.

Docker 모델 러너에서 컨텍스트 크기 구성 및 대안 마련
Docker 모델 러너에서 컨텍스트 크기 구성은 예상보다 더 복잡한 경우가 많습니다.

텍스트 지시문으로 이미지를 강화하는 AI 모델
블랙 포레스트 랩스는 텍스트 지시문을 사용하여 기존 이미지를 향상시키는 고급 이미지에서 이미지로 생성하는 AI 모델인 FLUX.1-Kontext-dev를 출시했습니다.

NVIDIA CUDA 지원을 통해 Docker 모델 실행기에서 GPU 가속을 활성화하세요.
Docker Model Runner은 AI 모델을 로컬에서 실행하는 Docker의 공식 도구이지만,
Docker Model Runner에서 NVidia GPU 가속 기능 활성화
은 특정 설정이 필요합니다.

스마트 토큰 최적화로 LLM 비용을 80% 절감하세요
토큰 최적화는 예산을 소모하는 실험에서 비용 효율적인 LLM(대규모 언어 모델) 애플리케이션을 구분하는 핵심 기술입니다.

GPT-OSS 120b의 세 AI 플랫폼에서의 벤치마크
저는 Ollama에서 실행되는 GPT-OSS 120b의 성능 테스트 결과를 NVIDIA DGX Spark, Mac Studio, RTX 4080 세 가지 플랫폼에서 확인해보았습니다. Ollama 라이브러리에서 제공하는 GPT-OSS 120b 모델의 크기는 65GB로, RTX 4080의 16GB VRAM에 맞지 않으며, 더 최근의 RTX 5080에도 맞지 않습니다.

AI 어시스턴트를 위한 MCP 서버를 Python 예제와 함께 구축하세요.
모델 컨텍스트 프로토콜(MCP)은 AI 어시스턴트가 외부 데이터 소스 및 도구와 상호 작용하는 방식을 혁신하고 있습니다. 이 가이드에서는 웹 검색 및 스크래핑 기능에 초점을 맞춘 MCP 서버를 Python으로 구축 방법을 살펴보겠습니다.

HTML을 깨끗하고 LLM에 적합한 Markdown으로 변환하는 Python
HTML을 Markdown으로 변환은 웹 콘텐츠를 대규모 언어 모델(LLM), 문서 시스템, 또는 Hugo와 같은 정적 사이트 생성기로 준비하는 현대 개발 워크플로우에서 근본적인 작업입니다. 이 가이드는 우리의 2026년 문서 도구: Markdown, LaTeX, PDF 및 인쇄 워크플로우 허브의 일부입니다.