
GNOME Boxes: 기능, 장점, 도전 과제 및 대안에 대한 종합 가이드
GNOME Boxes를 사용한 Linux용 간단한 가상 머신 관리
현대 컴퓨팅 환경에서 가상화는 개발, 테스트, 여러 운영 체제의 실행에 필수적인 요소가 되었습니다. Linux 사용자들이 가상 머신을 관리하는 데 간단하고 직관적인 방법을 원한다면, GNOME Boxes는 기능성을 희생하지 않고 사용 편의성을 중시하는 가벼운 사용자 친화적인 옵션으로 두드러집니다.
GNOME Boxes를 사용한 Linux용 간단한 가상 머신 관리
현대 컴퓨팅 환경에서 가상화는 개발, 테스트, 여러 운영 체제의 실행에 필수적인 요소가 되었습니다. Linux 사용자들이 가상 머신을 관리하는 데 간단하고 직관적인 방법을 원한다면, GNOME Boxes는 기능성을 희생하지 않고 사용 편의성을 중시하는 가벼운 사용자 친화적인 옵션으로 두드러집니다.

전문적인 칩이 AI 추론을 더 빠르고 저렴하게 만들어가고 있습니다.

6 개 국가의 가용성, 실제 소매 가격 및 Mac Studio 와의 비교.
NVIDIA DGX Spark 는 실존하며, 2025 년 10 월 15 일에 출시되어 통합 NVIDIA AI 스택을 갖춘 로컬 LLM 작업이 필요한 CUDA 개발자를 대상으로 합니다. 미국 권장 소매가 (MSRP) 는 3,999 달러이며, 영국/독일/일본의 소매가는 부가가치세 (VAT) 와 유통 채널 비용으로 인해 더 높습니다. 호주/한국의 공개 스티커 가격은 아직 널리 발표되지 않았습니다.

AI 에 적합한 소비자용 GPU 가격 - RTX 5080 과 RTX 5090
LLM 을 비롯한 AI 작업에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 특히 RTX-5080 과 RTX-5090 가격 에 주목합니다. 가격이 약간 하락했습니다.
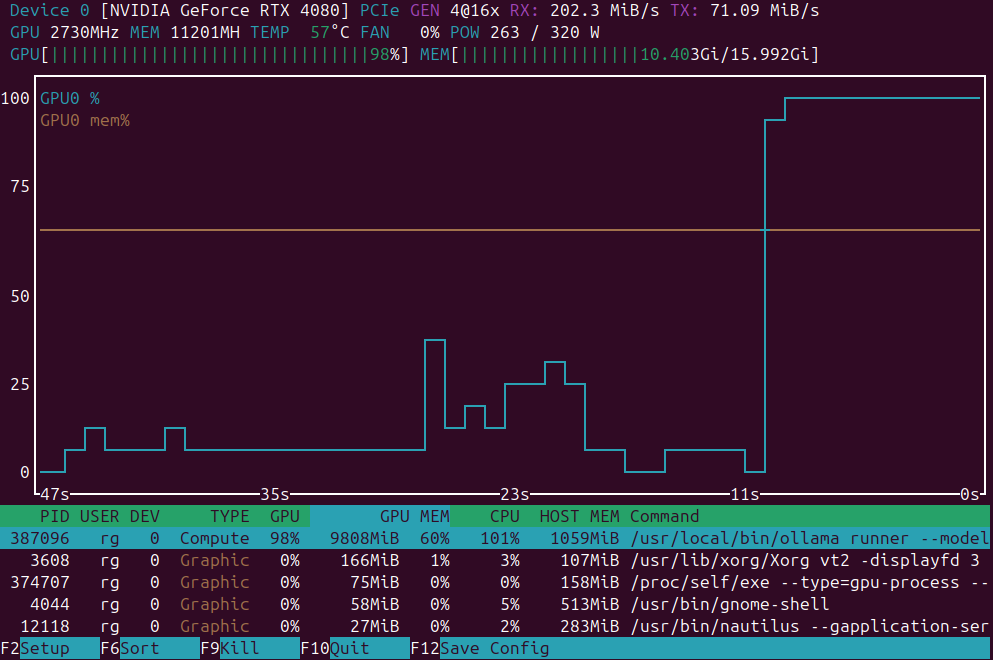
GPU 부하 모니터링을 위한 애플리케이션 목록
GPU 로드 모니터링 애플리케이션: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

2025 년 7 월이면 곧 이용 가능할 것입니다.
Nvidia 가 곧 NVIDIA DGX Spark를 출시합니다. 128GB 이상의 통합 RAM 과 1 PFLOPS AI 성능을 갖춘 블랙웰 (Blackwell) 아키텍처 기반의 소형 AI 슈퍼컴퓨터입니다. LLM 을 실행하기에 훌륭한 기기입니다.

AI 적합 GPU 가격 업데이트 - RTX 5080 및 RTX 5090
2026 년의 컴퓨팅 하드웨어, 특히 LLM 과 AI 전반에 적합한 최상위 소비자용 GPU 의 가격을 비교해 보겠습니다. 구체적으로는 RTX 5080 과 RTX 5090 가격 을 살펴보세요. 가격이 약간 하락했습니다.

가격 현실 점검 - RTX 5080 과 RTX 5090
3 개월 전까지만 해도 상점에서 RTX 5090 을 찾아볼 수 없었는데, 이제는 등장했지만 가격은 권장 소비자 가격 (MRSP) 보다 약간 높은 편입니다. 가장 저렴한 호주 내 RTX 5080 과 RTX 5090 가격 을 비교해보고 상황이 어떻게 변했는지 확인해 보겠습니다.
참고로 2025 년 7 월 호주 내 RTX 5080 과 RTX 5090 가격, 2025 년 10 월, 그리고 2025 년 11 월 자료도 함께 참고해 보세요.

더 많은 RAM, 더 낮은 전력 소모, 하지만 여전히 비싸고...
위대한 업무를 위한 최상의 자동화 시스템.

LLM용으로 두 번째 GPU를 설치할 생각이신가요?
PCIe 랜의 수가 LLM 성능에 미치는 영향? 작업에 따라 다릅니다. 훈련 및 멀티 GPU 추론의 경우 성능 저하가 상당합니다.

그리고 왜 내가 이 BSOD를 계속 보고 있는 건가...
이 문제로 인해 큰 충격을 받았습니다. 하지만 BSOD가 제게와 비슷한 경우라면, 자신의 PC를 조사하고 테스트해 보는 것이 좋습니다. 원인은 인텔 13세대 및 14세대 CPU의 성능 저하 문제입니다.

인텔 CPU의 효율성 코어 vs 성능 코어에서의 Ollama
제가 테스트하고 싶은 이론은, 인텔 CPU에서 모든 코어를 사용하면 LLM의 속도가 빨라질까?입니다.
새로운 gemma3 27비트 모델(gemma3:27b, ollama에서 17GB)이 제 GPU의 16GB VRAM에 맞지 않아, 부분적으로 CPU에서 실행되고 있다는 점이 제게 짜증을 주고 있습니다.

AI는 많은 컴퓨팅 파워가 필요합니다...
현대 세계의 혼란 속에서 저는 다른 카드의 기술 사양 비교를 진행하고 있습니다. 이는 AI 작업에 적합한 카드들입니다.
(딥러닝,
객체 감지,
LLMs).
하지만 이 모든 카드는 매우 비싸죠.

병렬 요청 실행을 위해 ollama 구성하기.
Ollama 서버가 동일한 시간에 두 개의 요청을 받을 경우, 그 동작은 구성 설정과 사용 가능한 시스템 자원에 따라 달라집니다.

기존 프린터 드라이버와 비교해 훨씬 간단합니다.
ET-8500을 Windows에 설치하는 방법은 매뉴얼에 잘 설명되어 있습니다. ET-8500 Linux 드라이버 설치는 간단하지만 복잡한 부분도 있습니다. 이 가이드는 우리의 2026년 문서화 도구: Markdown, LaTeX, PDF 및 인쇄 워크플로우 허브의 일부입니다.

GPU 대 CPU에서 LLM의 속도를 테스트해 보겠습니다.
다양한 버전의 LLM(llama3, phi3, gemma, mistral)의 예측 속도를 CPU와 GPU에서 비교합니다.