GNOME Boxes: Una guía completa sobre características, ventajas, desafíos y alternativas
Gestión sencilla de máquinas virtuales para Linux con GNOME Boxes
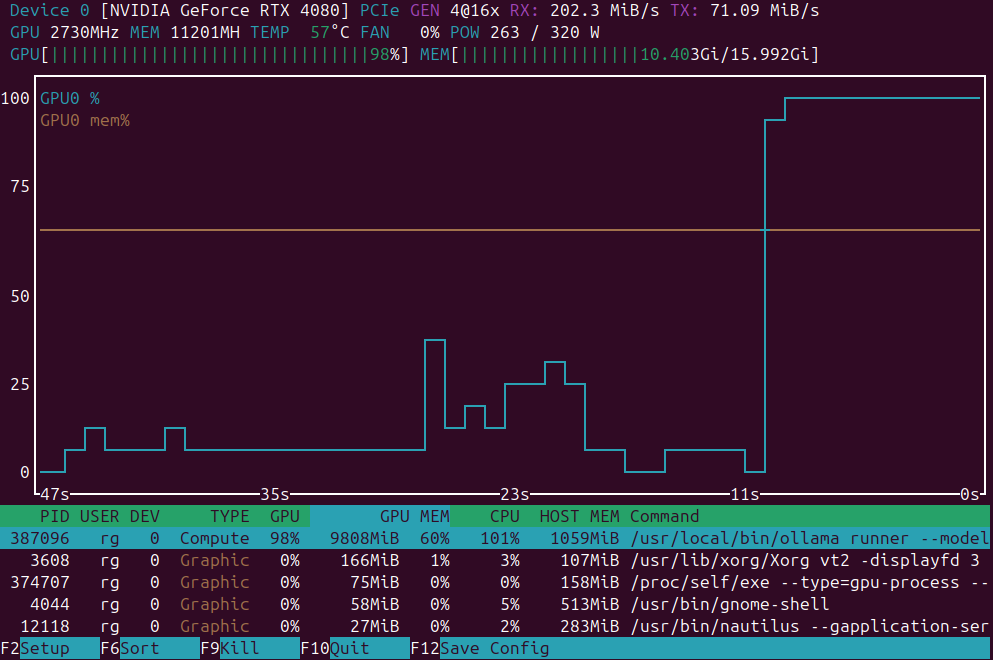
En el panorama actual de la computación, la virtualización se ha convertido en esencial para el desarrollo, las pruebas y la ejecución de múltiples sistemas operativos. Para usuarios de Linux que buscan una forma sencilla e intuitiva de gestionar máquinas virtuales, GNOME Boxes destaca como una opción liviana y amigable con el usuario que prioriza la facilidad de uso sin sacrificar la funcionalidad.