Chunking är den * mest undervärderade * hyperparametern i Retrieval ‑ Augmenterad Generering (RAG):
den bestämmer tyst och osynligt vad din LLM “ser”,
hur dyrt ingångsarbete blir,
och hur mycket av LLM:s kontextfönster du förbrukar per svar.
Att köra stora språkmodeller lokalt ger dig integritet, möjlighet att använda dem offline och noll kostnader för API:er.
Detta benchmark visar exakt vad man kan förvänta sig från 14 populära
LLMs på Ollama på en RTX 4080.
Idag tittar vi på de högsta nivåerna av konsumentspelkort och RAM-moduler.
Specifikt tittar jag på
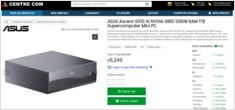
RTX-5080 och RTX-5090-priser, och 32GB (2x16GB) DDR5 6000.
Verkliga AUD-priser från australiska återförsäljare nu
NVIDIA DGX Spark
(https://www.glukhov.org/sv/hardware/ai/nvidia-dgx-spark/ “NVIDIA DGX Spark - liten AI-superdator”)
(GB10 Grace Blackwell) är nu tillgänglig i Australien
(https://www.glukhov.org/sv/hardware/ai/dgx-spark-pricing-in-australia/ “DGX Spark i Australien”)
hos större datorhandlare med lokalt lager.
Om du har följt
globala priser och tillgänglighet för DGX Spark,
är du kanske intresserad av att veta att priserna i Australien ligger mellan 6 249 och 7 999 AUD beroende på lagringskonfiguration och återförsäljare.
Efter att ha installerat en ny kernel automatiskt, har Ubuntu 24.04 förlorat ethernetnätverket. Detta frustrerande problem uppstod för mig en andra gång, så jag dokumenterar lösningen här för att hjälpa andra som stöter på samma problem.
Implementera företags AI på budgetmaskinvaru med öppna modeller.
Demokratiseringen av AI är här.
Med öppna källkodsmodeller som Llama, Mistral och Qwen som nu är jämbördiga med proprietära modeller, kan team bygga kraftfull AI-infrastruktur med konsumenthårdvara – vilket sänker kostnaderna kraftigt samtidigt som man behåller full kontroll över dataprivacy och implementering.
GPT-OSS 120b-benchmärkningar på tre AI-plattformar
Jag hittade några intressanta prestandatest av GPT-OSS 120b som kör på Ollama över tre olika plattformar: NVIDIA DGX Spark, Mac Studio, och RTX 4080. GPT-OSS 120b-modellen från Ollama-biblioteket väger 65 GB, vilket innebär att den inte passar in i den 16 GB VRAM som finns på en RTX 4080 (eller den nyare RTX 5080).
Docker Model Runner (DMR) är Docks officiella lösning för att köra AI-modeller lokalt, introducerad i april 2025. Den här cheatsheten ger en snabb referens för alla viktiga kommandon, konfigurationer och bästa praxis.