

Zmniejsz koszty LLM: strategie optymalizacji tokenów
Zredukuj koszty LLM o 80% dzięki inteligentnej optymalizacji tokenów
Optymalizacja tokenów to kluczowe umiejętności, które oddzielają kosztowne aplikacje LLM od doświadczeń zużycia budżetu.
Zredukuj koszty LLM o 80% dzięki inteligentnej optymalizacji tokenów
Optymalizacja tokenów to kluczowe umiejętności, które oddzielają kosztowne aplikacje LLM od doświadczeń zużycia budżetu.

Tworzenie serwerów MCP dla asystentów AI z przykładami w Pythonie
Protokół Kontekstu Modelu (MCP) rewolucjonizuje sposób, w jaki asystenci AI interagują z zewnętrznymi źródłami danych i narzędziami. W tym przewodniku omówimy, jak zbudować serwery MCP w Pythonie, z przykładami skupionymi na możliwościach wyszukiwania w sieci i skrapowania.

Slightly different APIs require special approach. Slightly different APIs require special approach.
Oto porównanie wsparcia w formie obok siebie dla strukturalnego wyjścia (otrzymywanie niezawodnego JSON) wśród popularnych dostawców LLM, wraz z minimalnymi przykładami w Pythonie

Kilka sposobów na uzyskanie strukturalnego wyjścia z Ollama
Duże modele językowe (LLMs)
są potężne, ale w środowisku produkcyjnym rzadko chcemy wolnych paragrafów.
Zamiast tego chcemy przewidywalne dane: atrybuty, fakty lub strukturalne obiekty, które można przekazać do aplikacji.
To Strukturalne wyjście LLM.
Opis, lista poleceń i skróty klawiatury
Oto najnowszy arkusz wskazówek GitHub Copilot, zawierający istotne skróty, polecenia, wskazówki dotyczące użycia oraz funkcje kontekstowe dla Visual Studio Code i Copilot Chat
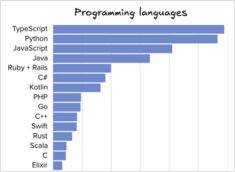
Porównanie narzędzi i języków inżynierii oprogramowania
Liczba przesłanych danych z ankiety o popularność języków programowania, IDE i narzędzi AI z kilku dni temu została opublikowana w liście The Pragmatic Engineer popularność języków programowania, IDE i narzędzi AI oraz inne dane na temat połowy 2025 roku.

W lipcu 2025 roku, wkrótce będzie dostępny.
Nvidia wkrótce wypuści NVIDIA DGX Spark – mały superkomputer AI oparty na architekturze Blackwell, z ponad 128 GB pamięci unifikowanej i wydajnością AI na poziomie 1 PFLOPS. Wspaniałe urządzenie do uruchamiania LLM.

Długi artykuł o specyfikacjach i implementacji MCP w GO
Oto opis Protokołu Kontekstu Modelu (MCP), krótkie uwagi dotyczące sposobu implementacji serwera MCP w Go, w tym struktura wiadomości i specyfikacja protokołu.

Wdrażasz RAG? Oto kilka fragmentów kodu w Go – część 2...
Ponieważ standardowe Ollama nie posiada bezpośredniego interfejsu API do ponownego rankingu (reranking), musisz zaimplementować ponowny ranking przy użyciu Qwen3 Reranker w GO, generując wektory (embeddings) dla par zapytanie-dokument i przypisując im oceny.
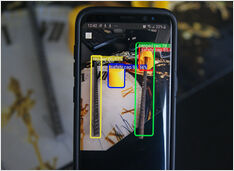
Nieco wcześniej wytrenowałem AI wykrywania obiektów.
W jednym zimnym zimnym dniu w lipcu … czyli w Australii … czułem nagły potrzebę trenowania modelu AI do wykrywania nierozpaczonych prętów zbrojeniowych w betonie…

Wdrażasz RAG? Oto kilka fragmentów kodu w języku Golang.
Ten niewielki przykład kodu Go do rerankingu wywołuje Ollamę do generowania wektorów dla zapytania oraz dla każdego dokumentu kandydackiego, następnie sortuje wyniki malejąco według podobieństwa kosinusowego.

Nowe, imponujące modele LLM dostępne w Ollama
Modele Qwen3 Embedding i Reranker (https://www.glukhov.org/pl/rag/embeddings/qwen3-embedding-qwen3-reranker-on-ollama/ “Modele Qwen3 Embedding i Reranker na platformie ollama”) to najnowsze wydania z rodziny Qwen, zaprojektowane specjalnie do zaawansowanych zadań związanych z tworzeniem wektorów tekstu (embedding), odnajdywaniem informacji (retrieval) oraz ponownym ocenianiem wyników (reranking).

Co to jest ta nałogowa programowanie wspomagana AI?
Vibe coding to podejście do programowania napędowane przez sztuczną inteligencję, w którym programiści opisują pożądaną funkcjonalność w języku naturalnym, pozwalając narzędziom AI na automatyczne generowanie kodu.

Cały zestaw narzędzi MM* jest na końcu cyklu życia...
Używałem MMDetection (mmengine, mdet, mmcv) dość często,
a teraz wygląda na to, że wycofał się z gry.
To żal. Lubiłem jego zoo modeli.

Świetny nowy model AI do generowania obrazu na podstawie tekstu
Niedawno Black Forest Labs opublikowała zestaw modeli AI tekst-do-obrazu text-to-image AI models.
Te modele mają być znane z znacznie wyższej jakości wyjściowych obrazów.
Spróbujmy ich

Porównanie dwóch samodzielnie hostowanych silników wyszukiwania AI
Świetna jedzenie to przyjemność dla oczu również. Ale w tym poście porównamy dwa systemy wyszukiwania oparte na AI, Farfalle i Perplexica.