Métricas, paneles de control y alertas para sistemas de producción — Prometheus, Grafana, Kubernetes y cargas de trabajo de inteligencia artificial.
Observabilidad es la base de sistemas de producción confiables.
Sin métricas, dashboards y alertas, los clústeres de Kubernetes se desvían, las cargas de trabajo de IA fallan en silencio y las regresiones de latencia pasan desapercibidas hasta que los usuarios se quejan.
De RAG básico a producción: fragmentación, búsqueda vectorial, reranking y evaluación en una sola guía.
Production-focused guide to building RAG systems: chunking, vector stores, hybrid retrieval, reranking, evaluation, and when to choose RAG over fine-tuning.
Strategic guide to hosting large language models locally with Ollama, llama.cpp, vLLM, or in the cloud. Compare tools, performance trade-offs, and cost considerations.
A performance engineering hub for running LLMs efficiently: runtime behavior, bottlenecks, benchmarks, and the real constraints that shape throughput and latency.
Controla los datos y los modelos con LLMs autohospedados
Autohospedaje de LLMs mantiene los datos, modelos e inferencia bajo su control: un camino práctico hacia la soberanía en IA para equipos, empresas y naciones.
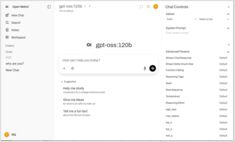
Prueba de velocidad de LLM en RTX 4080 con 16 GB de VRAM
Ejecutar modelos de lenguaje grandes localmente te brinda privacidad, capacidad para trabajar sin conexión y cero costos de API.
Este benchmark revela exactamente lo que se puede esperar de 14 modelos populares
LLMs en Ollama en una RTX 4080.
Repositorios de Python en tendencia de enero de 2026
El ecosistema de Python de este mes está dominado por las habilidades de Claude y las herramientas para agentes de IA.
Este análisis analiza los
repositorios de Python más populares en GitHub.
El ecosistema de Rust está explotando con proyectos innovadores, especialmente en herramientas de codificación de IA y aplicaciones de terminal.
Este análisis examina los mejores repositorios de Rust trending en GitHub de este mes.
El ecosistema de Go continúa prosperando con proyectos innovadores que abarcan herramientas de IA, aplicaciones autohospedadas y infraestructura para desarrolladores. Este análisis examina los repositorios de Go más trending en GitHub de este mes.
vLLM es un motor de inferencia y servicio de alto rendimiento y eficiente en memoria para Modelos de Lenguaje Grandes (LLM), desarrollado por el Laboratorio de Computación Sky de la Universidad de California, Berkeley.
Precios reales en AUD de minoristas australianos ahora
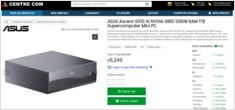
El
NVIDIA DGX Spark
(GB10 Grace Blackwell) ya está
disponible en Australia
en los principales minoristas de PC con stock local.
Si has estado siguiendo los
precios y disponibilidad globales del DGX Spark,
te interesará saber que los precios en Australia oscilan entre $6.249 y $7.999 AUD, dependiendo de la configuración de almacenamiento y del minorista.
Guía técnica para la detección de contenido generado por IA
La proliferación de contenido generado por IA ha creado un nuevo desafío: distinguir entre escritura humana auténtica y “IA slop” - texto sintético de baja calidad, producido en masa.
Cuando se trabaja con Modelos de Lenguaje Grande en producción, obtener salidas estructuradas y seguras en cuanto al tipo es crítico.
Dos marcos populares — BAML y Instructor — toman enfoques diferentes para resolver este problema.
Elegir el Mejor LLM para Cognee requiere equilibrar la calidad de construcción de gráficos, las tasas de alucinación y las restricciones de hardware.
Cognee destaca con modelos grandes de baja alucinación (32B+) a través de Ollama pero las opciones de tamaño medio funcionan para configuraciones más ligeras.