
Modelos de Embedding y Reranker de Qwen3 en Ollama: Rendimiento de vanguardia
Nuevos modelos de LLM impresionantes disponibles en Ollama
Los modelos Qwen3 Embedding y Reranker son los últimos lanzamientos de la familia Qwen, diseñados específicamente para tareas avanzadas de incrustación de texto, recuperación y reordenamiento.
Alegría para la vista
Los modelos Qwen3 Embedding y Reranker representan un avance significativo en el procesamiento del lenguaje natural (PLN) multilingüe, ofreciendo un rendimiento de última generación en tareas de incrustación y reordenamiento de texto. Estos modelos, parte de la serie Qwen desarrollada por Alibaba, están diseñados para soportar una amplia gama de aplicaciones, desde la recuperación semántica hasta la búsqueda de código. Este tipo de capacidad de incrustación es fundamental para construir sistemas RAG efectivos, como se detalla en el Tutorial de Generación Aumentada por Recuperación (RAG): Arquitectura, Implementación y Guía de Producción. Aunque Ollama es una plataforma de código abierto popular para alojar y desplegar modelos de lenguaje grandes (LLM), la integración de los modelos Qwen3 con Ollama no se detalla explícitamente en la documentación oficial. Sin embargo, los modelos están disponibles a través de Hugging Face, GitHub y ModelScope, lo que habilita el despliegue local potencial a través de Ollama o herramientas similares.
Ejemplos utilizando estos modelos
Consulta el código de ejemplo en Go utilizando ollama con estos modelos:
- Reordenamiento de documentos de texto con Ollama y el modelo Qwen3 Embedding - en Go
- Reordenamiento de documentos de texto con Ollama y el modelo Qwen3 Reranker - en Go
Visión general de los nuevos modelos Qwen3 Embedding y Reranker en Ollama
Estos modelos están ahora disponibles para su despliegue en Ollama en varios tamaños, proporcionando un rendimiento de última generación y flexibilidad para una amplia gama de aplicaciones relacionadas con el lenguaje y el código.
Características y capacidades clave
-
Tamaños del modelo y flexibilidad
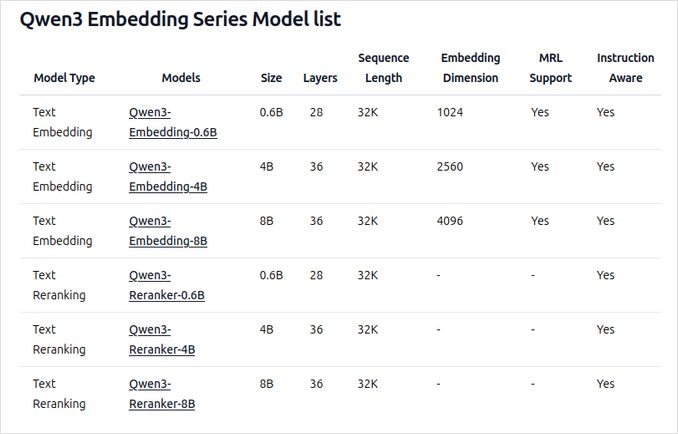
- Disponibles en múltiples tamaños: 0.6B, 4B y 8B parámetros para tareas de incrustación y reordenamiento.
- El modelo de incrustación de 8B ocupa actualmente el lugar No. 1 en la clasificación multilingüe MTEB (a fecha del 5 de junio de 2025, con una puntuación de 70.58).
- Soporta una variedad de opciones de cuantización (Q4, Q5, Q8, etc.) para equilibrar rendimiento, uso de memoria y velocidad. Se recomienda Q5_K_M para la mayoría de los usuarios, ya que preserva la mayor parte del rendimiento del modelo mientras es eficiente en recursos.
-
Arquitectura y entrenamiento
- Construidos sobre la base de Qwen3, aprovechando tanto arquitecturas de codificador dual (para incrustaciones) como codificador cruzado (para reordenamiento).
- Modelo de incrustación: Procesa segmentos de texto individuales, extrayendo representaciones semánticas del estado oculto final.
- Modelo Reranker: Toma pares de texto (por ejemplo, consulta y documento) y genera una puntuación de relevancia utilizando un enfoque de codificador cruzado.
- Los modelos de incrustación utilizan un paradigma de entrenamiento de tres etapas: pre-entrenamiento contrastivo, entrenamiento supervisado con datos de alta calidad y fusión de modelos para una generalización y adaptabilidad óptimas.
- Los modelos Reranker se entrenan directamente con datos etiquetados de alta calidad para eficiencia y efectividad.
-
Soporte multilingüe y multitarea
- Soporta más de 100 idiomas, incluidos lenguajes de programación, lo que habilita capacidades robustas de recuperación multilingüe, interlingüe y de código.
- Los modelos de incrustación permiten definiciones de vectores flexibles e instrucciones definidas por el usuario para adaptar el rendimiento a tareas o idiomas específicos.
- Para aplicaciones que requieren capacidades multimodales más allá del texto, consulta Incrustaciones Transmodales: Conectando Modalidades de IA.
-
Rendimiento y casos de uso
- Resultados de última generación en recuperación de texto, recuperación de código, clasificación, agrupamiento y minería de bitextos.
- Los modelos Reranker sobresalen en diversos escenarios de recuperación de texto y pueden combinarse perfectamente con modelos de incrustación para pipelines de recuperación de extremo a extremo.
Cómo usar en Ollama
Puedes ejecutar estos modelos en Ollama con comandos como:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Elige la versión de cuantización que mejor se adapte a tus necesidades de hardware y rendimiento.
Actualización diciembre 2025: Ahora Ollama proporciona modelos de incrustación Qwen3 estándar desde su propio repositorio, no el de dengcao:
ollama pull qwen3-embedding:8b
ollama pull qwen3-embedding:4b
Ver más: https://ollama.com/library/qwen3-embedding
Tabla resumen
| Tipo de Modelo | Tamaños Disponibles | Fortalezas Clave | Soporte Multilingüe | Opciones de Cuantización |
|---|---|---|---|---|
| Incrustación (Embedding) | 0.6B, 4B, 8B | Puntuaciones MTEB superiores, flexible, eficiente, SOTA | Sí (100+ idiomas) | Q4, Q5, Q6, Q8, etc. |
| Reranker | 0.6B, 4B, 8B | Sobresale en relevancia de pares de texto, eficiente, flexible | Sí | F16, Q4, Q5, etc. |
¡Noticias geniales!
Los modelos Qwen3 Embedding y Reranker en Ollama representan un salto significativo en las capacidades de recuperación de texto y código multilingües y multitarea. Con opciones de despliegue flexibles, un fuerte rendimiento en benchmarks y soporte para una amplia gama de idiomas y tareas, están bien adaptados tanto para entornos de investigación como de producción.
Zoológico de modelos - placer para la vista ahora
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
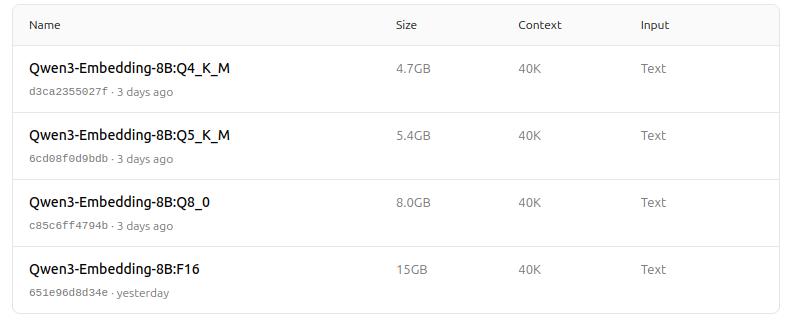
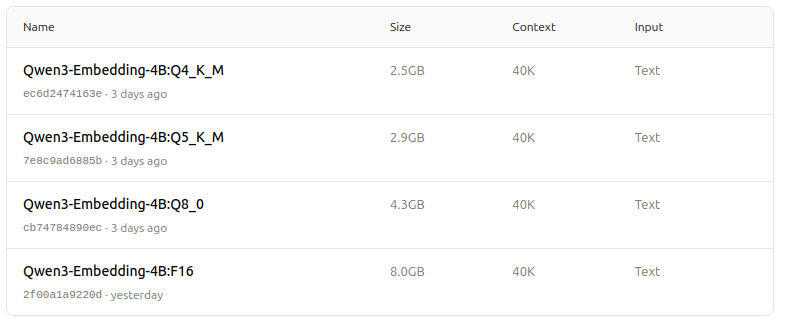
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
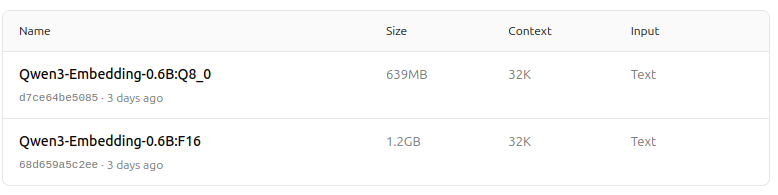
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
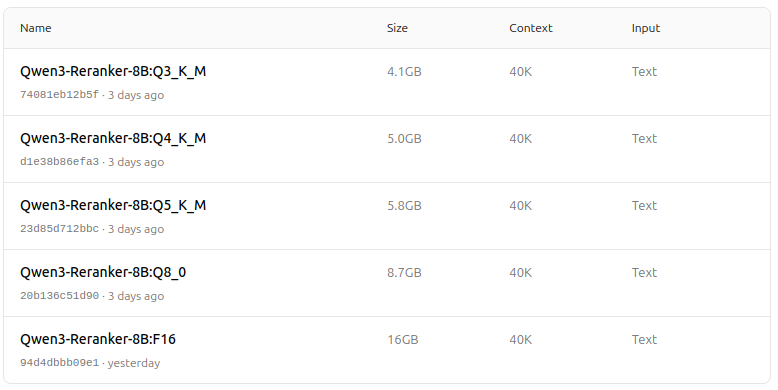
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
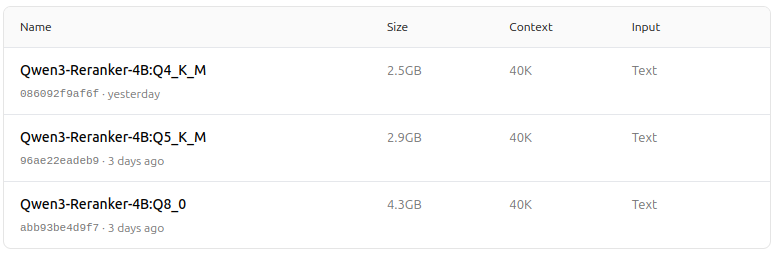
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
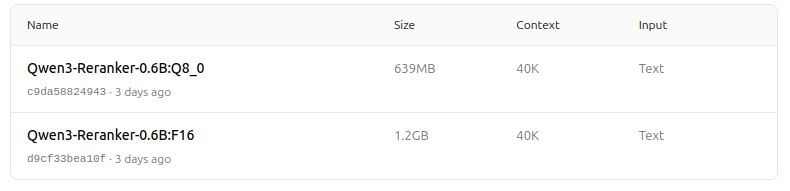
¡Genial!
Enlaces útiles
- Reordenamiento de documentos de texto con Ollama y el modelo Qwen3 Embedding - en Go
- Reordenamiento de documentos de texto con Ollama y el modelo Qwen3 Reranker - en Go
- Hoja de trucos de Ollama
- Mover modelos de Ollama a una unidad o carpeta diferente
- Autoalojamiento de Perplexica - con Ollama
- Prueba: Cómo Ollama utiliza el rendimiento del CPU Intel y núcleos eficientes
- Comparación de rendimiento de velocidad de LLM
- Comparación de capacidades de resumen de LLM
- Proveedores de LLM en la nube
- Cómo Ollama maneja las solicitudes paralelas
- Comparación de la calidad de traducción de páginas de Hugo - LLMs en Ollama
