
Modeli Qwen3 Embedding & Reranker na Ollama: Stanowi najnowsze osiągnięcia w zakresie wydajności
Nowe, wspaniałe modele LLM dostępne w Ollama
Modele Qwen3 Embedding i Reranker to najnowsze wersje w rodzinie Qwen, specjalnie zaprojektowane do zaawansowanych zadań w zakresie wstawiania tekstu, wyszukiwania i ponownego rangowania.
Radość dla oka
Modele Qwen3 Embedding i Reranker reprezentują znaczący postęp w przetwarzaniu języka naturalnego (NLP) wielojęzycznym, oferując najnowocześniejszą wydajność w zadaniach wstawiania i ponownego rangowania tekstu. Te modele, które są częścią serii Qwen opracowanej przez Alibaba, zostały zaprojektowane w celu wspierania szerokiego zakresu aplikacji, od wyszukiwania semantycznego po wyszukiwanie kodu. Choć Ollama to popularna platforma open source do hostowania i wdrażania dużych modeli językowych (LLM), integracja modeli Qwen3 z Ollama nie jest szczegółowo opisana w oficjalnej dokumentacji. Jednak modele są dostępne przez Hugging Face, GitHub i ModelScope, umożliwiając potencjalne lokalne wdrażanie za pomocą Ollama lub podobnych narzędzi.
Przykłady użycia tych modeli
Zobacz przykładowy kod w języku Go z użyciem ollama i tych modeli:
- Ponowne rangowanie dokumentów tekstowych z użyciem Ollama i modelu Qwen3 Embedding - w języku Go
- Ponowne rangowanie dokumentów tekstowych z użyciem Ollama i modelu Qwen3 Reranker - w języku Go
Omówienie nowych modeli Qwen3 Embedding i Reranker na Ollama
Te modele są teraz dostępne do wdrożenia na Ollama w różnych rozmiarach, oferując najnowocześniejszą wydajność i elastyczność dla szerokiego zakresu aplikacji związanych z językiem i kodem.
Główne cechy i możliwości
-
Rozmiary modeli i elastyczność
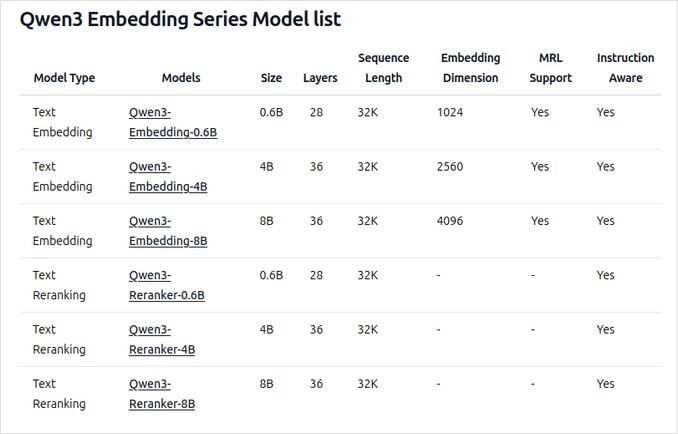
- Dostępne w wielu rozmiarach: 0,6B, 4B i 8B parametrów dla zadań wstawiania i ponownego rangowania.
- Obecnie model wstawiania 8B zajmuje pierwsze miejsce na wielojęzycznym rankingu MTEB (stan na 5 czerwca 2025 r., wynik 70,58).
- Obsługuje szereg opcji kwantyzacji (Q4, Q5, Q8 itp.) w celu balansowania wydajności, zużycia pamięci i prędkości. Wersja Q5_K_M jest zalecana dla większości użytkowników, ponieważ zachowuje większość wydajności modelu, jednocześnie będąc wydajna pod względem zasobów.
-
Architektura i trening
- Oparte na podstawie Qwen3, wykorzystujące zarówno architekturę dual-encoder (dla wstawiania), jak i cross-encoder (dla ponownego rangowania).
- Model wstawiania: przetwarza pojedyncze segmenty tekstu, wyodrębniając reprezentacje semantyczne z końcowego stanu ukrytego.
- Model ponownego rangowania: przyjmuje pary tekstowe (np. zapytanie i dokument) i wytwarza wynik rangowania przy użyciu podejścia cross-encoder.
- Modele wstawiania wykorzystują trzyetapowy model treningu: kontrastowy pre-trening, nadzorowany trening z wysokiej jakości danymi oraz łączenie modeli dla optymalnej generalizacji i elastyczności.
- Modele ponownego rangowania są trenowane bezpośrednio z wysokiej jakości etykietowanymi danymi w celu efektywności i skuteczności.
-
Wsparcie wielojęzyczne i wielozadaniowe
- Obsługuje ponad 100 języków, w tym języki programowania, zapewniając solidne możliwości wielojęzyczne, przekładowe i wyszukiwania kodu.
- Modele wstawiania umożliwiają elastyczne definicje wektorów i instrukcje zdefiniowane przez użytkownika, umożliwiające dostosowanie wydajności do konkretnych zadań lub języków.
-
Wydajność i przypadki użycia
- Najnowocześniejsze wyniki w wyszukiwaniu tekstu, wyszukiwaniu kodu, klasyfikacji, grupowaniu i wydobyciu par tekstowych.
- Modele ponownego rangowania wyróżniają się w różnych scenariuszach wyszukiwania tekstu i mogą być łączone w sposób płynny z modelami wstawiania w celu pełnoprawnych potoków wyszukiwania.
Jak używać na Ollama
Możesz uruchomić te modele na Ollama za pomocą komend takich jak:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Wybierz wersję kwantyzacji, która najlepiej odpowiada Twoim potrzebom sprzętowym i wydajnościowym.
Tabela podsumowująca
| Typ modelu | Dostępne rozmiary | Kluczowe zalety | Wsparcie wielojęzyczne | Opcje kwantyzacji |
|---|---|---|---|---|
| Wstawianie | 0,6B, 4B, 8B | Najlepsze wyniki MTEB, elastyczne, wydajne, SOTA | Tak (ponad 100 języków) | Q4, Q5, Q6, Q8, itp. |
| Ponowne rangowanie | 0,6B, 4B, 8B | Wyróżnia się w ocenie par tekstu, wydajne, elastyczne | Tak | F16, Q4, Q5, itp. |
Świetna wiadomość!
Modele Qwen3 Embedding i Reranker na Ollama reprezentują znaczący postęp w możliwościach wielojęzycznego, wielozadaniowego wyszukiwania tekstu i kodu. Dzięki elastycznym opcjom wdrażania, silnej wydajności w testach i wsparciu dla szerokiego zakresu języków i zadań, są dobrze dopasowane zarówno do środowisk badawczych, jak i produkcyjnych.
ZOO modeli – radość dla oka teraz
Qwen3 Embedding
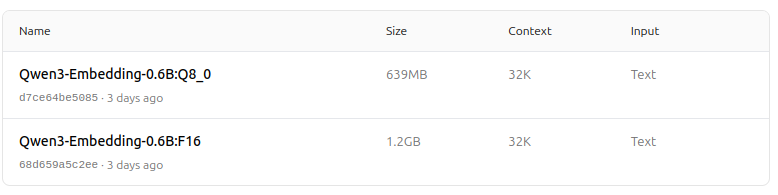
https://ollama.com/dengcao/Qwen3-Embedding-8B
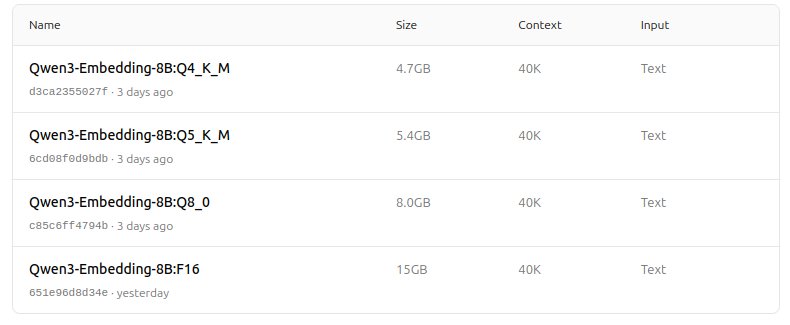
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
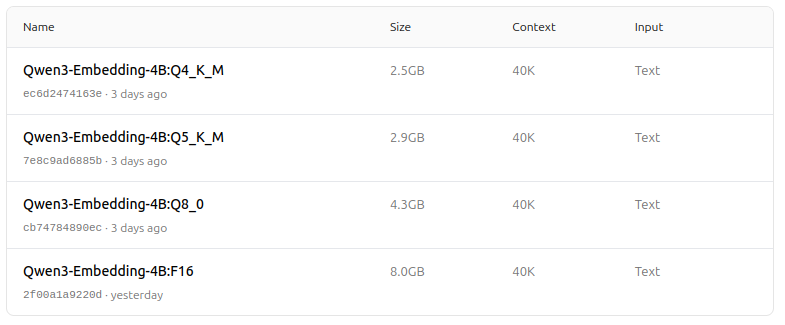
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
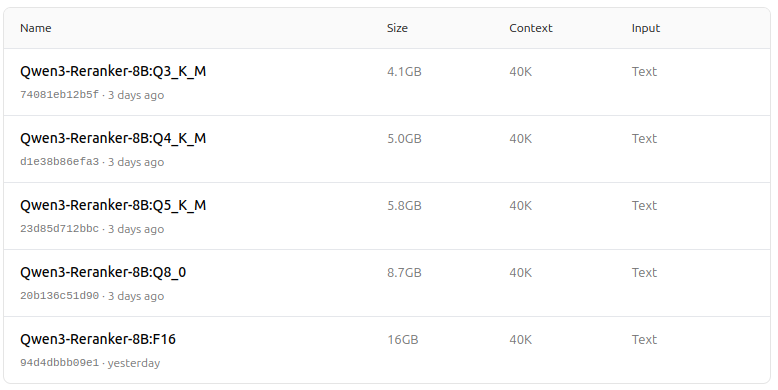 dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
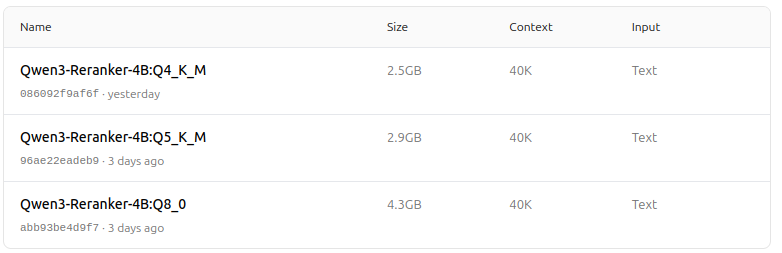
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
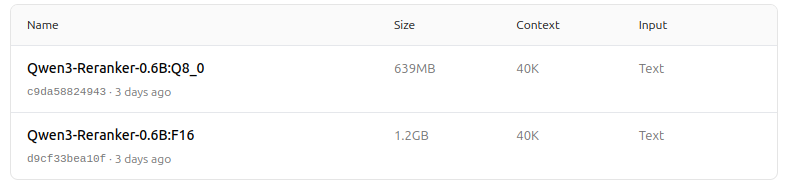
Świetnie!
Przydatne linki
- Ponowne rangowanie dokumentów tekstowych z użyciem Ollama i modelu Qwen3 Embedding - w języku Go
- Ponowne rangowanie dokumentów tekstowych z użyciem Ollama i modelu Qwen3 Reranker - w języku Go
- Ollama cheatsheet
- Przeniesienie modeli Ollama na inny dysk lub folder
- Samowystarczalne uruchamianie Perplexica - z użyciem Ollama
- Test: Jak Ollama wykorzystuje wydajność i efektywne jądra procesora Intel
- Porównanie wydajności modeli językowych
- Porównanie umiejętności sumaryzowania modeli językowych
- Dostawcy modeli językowych w chmurze
- Jak Ollama obsługuje żądania równoległe
- Porównanie jakości tłumaczenia stron Hugo – modele językowe na Ollama
