
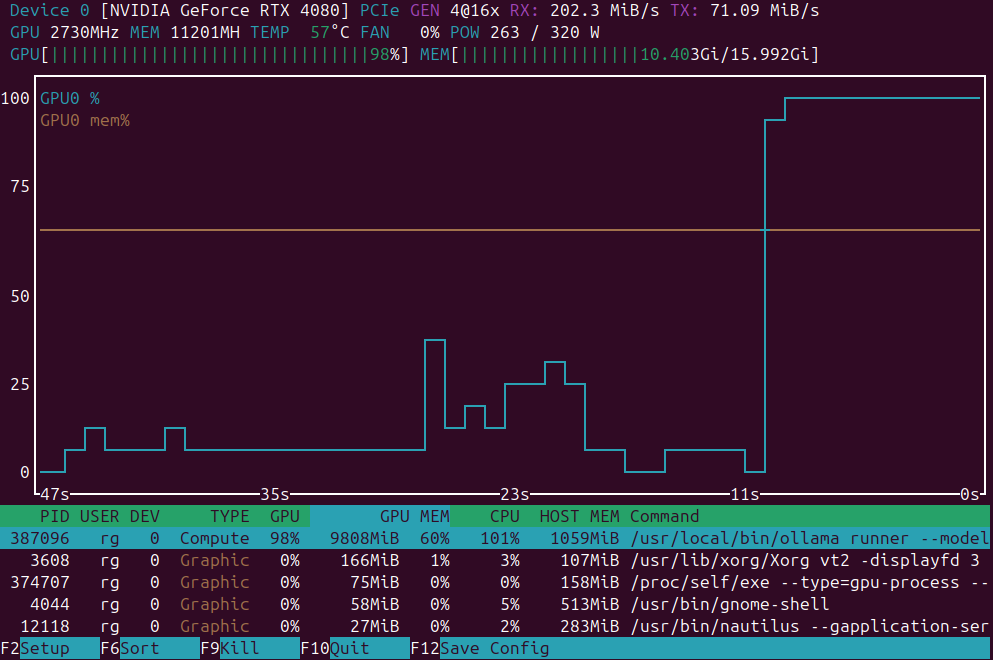
GPU-bewakingsapplicaties in Linux / Ubuntu
Korte lijst met toepassingen voor het monitoren van GPU-belasting
GPU belasting monitoring toepassingen: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.
Korte lijst met toepassingen voor het monitoren van GPU-belasting
GPU belasting monitoring toepassingen: nvidia-smi vs nvtop vs nvitop vs KDE plasma systemmonitor.

Installeren van little k3s Kubernetes op homelab-cluster
Hier is een stap-voor-stap walkthrough van
installatie van een 3-knooppunt K3s cluster
op bare-metal servers (1 master + 2 workers).

Zeer korte overzicht van kubernetes varianten
Vergelijking van self-hosting Kubernetes distributies voor het hosten op bare-metal of thuis-servers, met aandacht voor eenvoud van installatie, prestaties, systeemvereisten en functie-aanbod.
Het kiezen van de beste Kubernetes-variant voor onze homelab
Ik ben het vergelijken van self-hosted Kubernetes varianten die geschikt zijn voor de Ubuntu-gebaseerde homelab met 3 knooppunten (16 GB RAM, 4 cores elk), met aandacht voor eenvoud van installatie en onderhoud, ondersteuning voor persistente volumes en LoadBalancers.
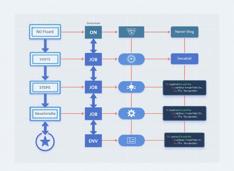
Een korte uitleg over gangbare GitHub Actions en hun structuur.
GitHub Actions is een automatiserings- en CI/CD-platform binnen GitHub, dat wordt gebruikt om code te bouwen, te testen en te implementeren op basis van gebeurtenissen zoals pushes, pull requests of volgens een schema.

Overigens is docker-compose anders dan docker compose...
Hier is een
Docker Compose naslagblad
met aangegeven voorbeelden om je snel te helpen Compose-bestanden en -opdrachten te beheersen.
Over Obsidian ...
Hier is een gedetailleerde uitleg over
Obsidian als krachtig hulpmiddel voor persoonlijke kennisbeheersing (PKM),
die de architectuur, functies, sterktes en hoe het moderne kennisstromen ondersteunt, uitlegt.

In juli 2025, het zou binnenkort beschikbaar moeten zijn.
Nvidia staat op het punt om de NVIDIA DGX Spark uit te brengen: een klein AI-supercomputerapparaat gebaseerd op de Blackwell-architectuur, met meer dan 128 GB unified RAM en een AI-prestatie van 1 PFLOPS. Een leuk apparaat om LLM’s op uit te voeren.
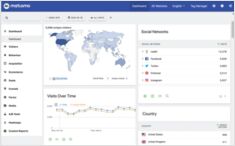
Welke webanalyse-systemen moet je gebruiken op je website?
Laat ons snel een kijkje nemen naar
Matomo, Plausible, google en andere webanalyseproviders en -systemen
die beschikbaar zijn voor zelfhosting en vergelijk ze.

Opmerkingen over de standaardinstallatievolgorde van Ubuntu 24.04
Hier is mijn favoriete set van stappen bij een nieuwe installatie van Ubuntu 24.04. Wat ik hier leuk vind – er hoeft geen NVidia drivers geïnstalleerd te worden! Ze worden automatisch geïnstalleerd.
Ik gebruikte Dokuwiki als persoonlijke kennisbank.
Dokuwiki is een zelfgehoste wikipedia https://www.glukhov.org/nl/post/2025/07/dokuwiki-selfhosted-wiki-alternatives/ “Dokuwiki” die gemakkelijk kan worden gehost op locatie en vereist geen databases. Ik draaide het dockerized, op mijn eigen kubernetes cluster.

Update van de prijzen voor voor AI geschikte GPU's – RTX 5080 en RTX 5090
Laten we de prijzen vergelijken voor top consumentengpu’s, die met name geschikt zijn voor LLM’s en AI in het algemeen. Kijk in het bijzonder naar de prijzen van de RTX 5080 en RTX 5090. Die zijn licht gedaald.

Mooi kader voor ETS/MLOPS met Python
Apache Airflow is een open-source platform dat is ontworpen om workflows programmatisch te schrijven, te plannen en te monitoren, volledig in Python-code, en biedt een flexibele en krachtige alternatief voor traditionele, manuele of UI-gebaseerde workflow-tools.

RAG implementeren? Hier zijn enkele codefragmenten in Go - deel 2...
Omdat standaard Ollama geen directe rerank-API heeft, moet je reranking implementeren met Qwen3 Reranker in GO door embeddings te genereren voor query-documentparen en deze te scoren.

qwen3 8b, 14b en 30b, devstral 24b, mistral small 24b
In deze test ben ik aan het vergelijken hoe verschillende LLMs die op Ollama worden gehost de Hugo-pagina vertalen van Engels naar Duits.

RAG implementeren? Hier zijn enkele codefragmenten in Golang..
Deze kleine Reranking Go-codevoorbeeld roept Ollama aan om embeddings te genereren voor de query en voor elk kandidaatdocument, en sorteer deze vervolgens aflopend op cosijnsimilariteit.