
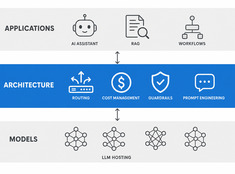
LLM-architectuur: systeemontwerp voor productie-AI
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
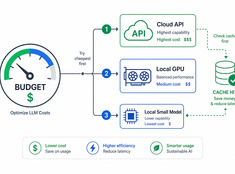
Besteed tokens waar het echt toe doet.
De kosten van LLM’s schalen lineair met het gebruik. Een systeem dat 10.000 verzoeken per dag verwerkt tegen $0,01 per verzoek kost dagelijks $100 — jaarlijks $365. Op enterprise-schaal is dat meer dan $10.000.
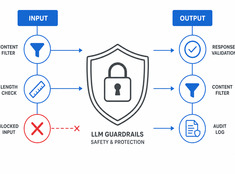
Beheers het risico, niet alleen het model.
LLM’s zijn onvoorspelbaar. Ze hallucineren, lekken data, genereren schadelijke content of weigeren legitieme verzoeken. Guardrails beperken het gedrag van modellen zonder in te leveren op capaciteit.
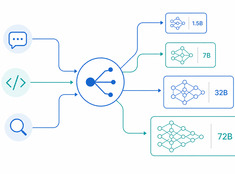
Het juiste model voor de juiste taak.
Het draaien van een model met 70 miljard parameters om een e-mail van 200 woorden samen te vatten, is zonde van de middelen. Het gebruiken van een model van 3 miljard parameters om productiecode te reviewen, is roekeloos. De meeste systemen zitten ergens daar tussenin — en daar komt modelrouting om de hoek kijken.
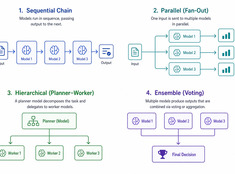
Kies het eenvoudigste patroon dat werkt.
Single-modelsystemen zijn eenvoudig. Multi-modelsystemen zijn krachtig. De uitdaging ligt niet in het kiezen van modellen, maar in het ontwerpen van de architectuur die ze orchestreert.

Werkend, gestructureerd en ophaalbaar geheugen voor assistenten.
Geheugen verandert assistenten van reactief naar persistent, maar het is ook waar veel systemen stil verlopen. Onderzoeken betoogen dat de splitsing tussen kortetermijn- en langetermijngeheugen niet langer voldoende is voor modern agentengeheugen; OpenAI en LangGraph SDK’s wijzen op een eenvoudigere stack — werkgeheugen, duurzame staat en ophaling.

Hoe serieuze assistants daadwerkelijk worden gebouwd.
Een productie-AI-assistent is niet zomaar “een LLM met een prompt”. Het is een systeem dat intentie accepteert, staat behoudt, beslist wanneer het moet ophalen of handelen, en voldoende runtime-details blootlegt om fouten te debuggen.

AI verandert kennismanagement, niet het doel ervan.
AI vervangt kennismanagement niet; het verandert de vorm ervan voor zowel individuen als teams.
Sterren, tokens, downloads — wie wint er eigenlijk?
Open-source AI-agentframeworks winnen explosief aan populariteit op GitHub. Twee projecten die centraal staan in het ecosysteem van zelfgehoste AI-systemen — OpenClaw en Hermes Agent — zijn zo ver vooruit gelopen dat de rest van het veld strijdt om een verre derde plaats.

MTP versus standaard decoding op de RTX 4080 — echte benchmarks
Ik heb de prestaties van speculatief decoderen (Multi-Token Prediction, MTP) getest in Qwen 3.6 27B en 35B op een RTX 4080 met 16 GB VRAM.

Gratis VRAM zonder llama-server te beëindigen.
Routermodus van llama.cpp is een van de meest nuttige wijzigingen aan llama-server in jaren. Het geeft lokale LLM-beheerders eindelijk iets dat lijkt op de modelbeheerservaring die mensen verwachten van Ollama, terwijl het de ruwe prestaties en lage-level controle behoudt die llama.cpp in de eerste plaats de moeite waard maken.

Gecompileerde kennis voor AI-systemen
De uitgangspunt is eenvoudig: gecompileerde kennis is herbruikbaarder dan opgeroepen fragmenten. RAG (Retrieval-Augmented Generation) is het standaardantwoord geworden op een eenvoudige vraag – hoe geef ik een LLM (Large Language Model) toegang tot externe kennis?

Een kaart van moderne kennisystemen
PKM, RAG, wikis, AI-geheugensystemen en nu praktische, door AI-assisted workflows worden vaak besproken alsof ze hetzelfde probleem oplossen. Dat doen ze niet. Ze hebben allemaal te maken met kennis, maar ze werken op verschillende lagen:

Stop met het interpreteren van vibes. Valideer contracten.
De meeste tutorials over “gestructureerde output” van GPT-modellen (LLM’s) zijn niet serieus. Ze leren je beleefd om JSON te vragen en hopen daarna dat het model zich gedraagt. Dat is geen validatie. Dat is optimisme met accolades.

Referentie voor het afstellen van agentische LLM’s
Deze pagina is een praktische referentie voor het afstemmen van agentische LLM-inferentie (temperatuur, top_p, top_k, penalties en hoe deze interacteren in meervoudige stappen en workflows met veel hulpmiddelen).

Gesprek voeren met Hermes vanaf je telefoon
Je chat al met Hermes Agent via je telefoon met tekst. Nu wil je er direct mee praten en gesproken antwoorden terugkrijgen. Dat is meestal de juiste zet, zeker als je al Hermes als een persistente, zelf gehoste assistent gebruikt. Het typen van lange prompts op een klein scherm is traag en foutgevoelig.