

Vergelijking AI-code-assistenten
Cursor AI versus GitHub Copilot versus Cline AI versus...
Hier vindt u een overzicht van enkele AI-gestuurde programmeringstools en hun vooruitvoordelen:
Cursor AI versus GitHub Copilot versus Cline AI versus...
Hier vindt u een overzicht van enkele AI-gestuurde programmeringstools en hun vooruitvoordelen:

Ollama op Intel CPU: Efficiëntie versus prestatiescores
Ik heb een theorie om te testen - als we alle kernen op een Intel CPU gebruiken, zou dat de snelheid van LLMs verhogen? Het irriteert me dat de nieuwe gemma3 27 bit model (gemma3:27b, 17 GB op ollama) niet in de 16 GB VRAM van mijn GPU past en gedeeltelijk op de CPU draait.

Ollama configureren voor het uitvoeren van parallelle aanvragen.
Wanneer de Ollama-server twee aanvragen tegelijkertijd ontvangt, hangt het gedrag ervan af van de configuratie en de beschikbare systeemresources.

Vergelijking van twee deepseek-r1-modellen met twee basismodellen
DeepSeek’s eerste generatie redeneingsmodellen met vergelijkbare prestaties als OpenAI-o1, waaronder zes dichte modellen gedistilleerd van DeepSeek-R1 gebaseerd op Llama en Qwen.

Bijgewerkte lijst met Ollama-opdrachten - ls, ps, run, serve, enz.
Deze Ollama CLI cheat sheet richt zich op de opdrachten die je elke dag gebruikt (ollama ls, ollama serve, ollama run, ollama ps, modelbeheer en veelvoorkomende workflows), met voorbeelden die je kunt kopiëren/pasten.

Volgende ronde LLM-tests
Niet zo lang geleden is vrijgegeven. Laten we even op de hoogte komen en test hoe Mistral Small presteert vergeleken met andere LLMs.

Een Python-code voor het herschikken van RAG.

Een vergelijking van twee zelfgehoste AI zoekmachines
Prachtige voedsel is ook een genot voor de ogen. Maar in dit bericht vergelijken we twee AI-gebaseerde zoeksystemen, Farfalle en Perplexica.
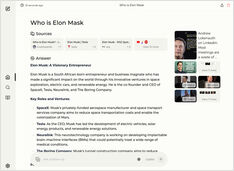
Een copilot-stijl service lokaal uitvoeren? Eenvoudig!
Dat is erg opwindend!
In plaats van copilot of perplexity.ai aan te roepen en aan de hele wereld te vertellen wat je zoekt,
kan je nu een soortgelijk dienst op je eigen PC of laptop hosten!

Testen van het detecteren van logische fouten
Onlangs hebben we meerdere nieuwe LLMs gezien die zijn vrijgegeven. Opwindende tijden. Laten we testen en zien hoe ze presteren bij het detecteren van logische fouten.
Niet zo veel om uit te kiezen, maar toch...
Toen ik begon met het experimenteren met LLMs waren de UIs voor hen actief in ontwikkeling en nu zijn sommige van hen echt goed.

Een beetje experimenteren vereist maar
Er zijn nog steeds enkele veelvoorkomende aanpakken om goede prompts te schrijven, zodat LLM’s niet in de war raken bij het begrijpen van wat je van hen wilt.

8 llama3 (Meta+) en 5 phi3 (Microsoft) LLM-versies
Testen hoe modellen met een verschillend aantal parameters en kwantificatie zich gedragen.

Ollama LLM-modelbestanden nemen veel ruimte in beslag
Na het installeren van ollama is het beter om ollama direct te herconfigureren om ze op een nieuwe plek op te slaan. Zo wordt er na het ophalen van een nieuw model niet naar de oude locatie gedownload.