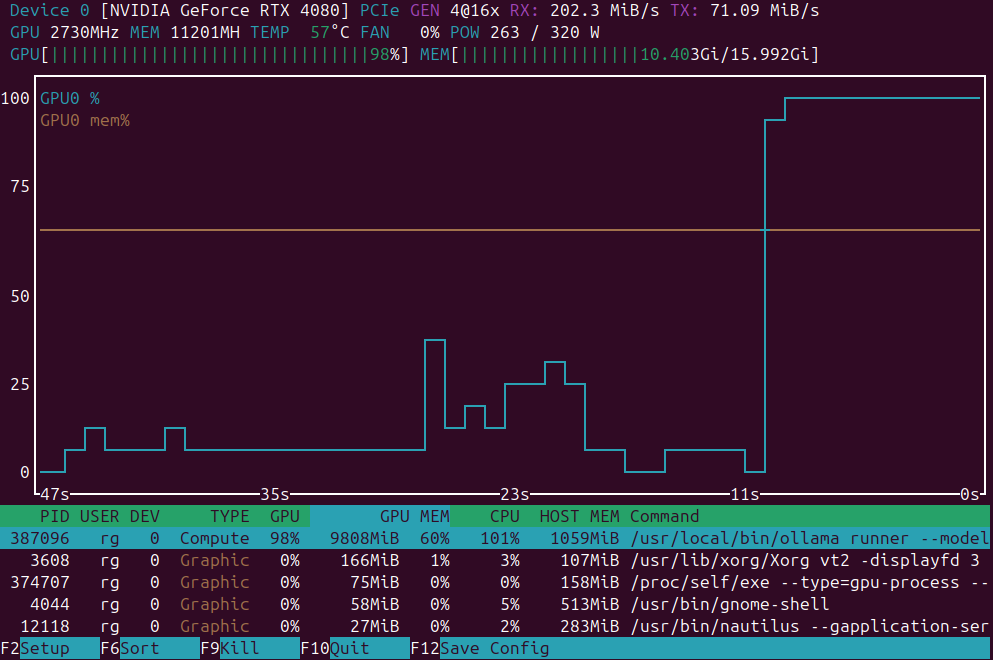
Vergelijking van LLM-prestaties op Ollama op een GPU met 16GB VRAM
LLM-snelheidstest op RTX 4080 met 16 GB VRAM
Het lokaal uitvoeren van grote taalmodellen biedt privacy, offline mogelijkheden en nul API-kosten. Deze benchmark laat precies zien wat men kan verwachten van 14 populaire LLMs op Ollama op een RTX 4080.