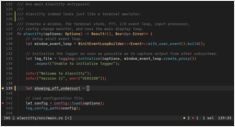
Chunking is de meest onderschatte hyperparameter in Retrieval ‑ Augmenteerde Generatie (RAG):
het bepaalt stilzwijgend wat je LLM “ziet”,
hoe duur de ingesting wordt,
en hoeveel van de contextwindow van de LLM je verbruikt per antwoord.
Self-hosting van LLMs houdt gegevens, modellen en inferentie onder jouw controle - een praktische weg naar AI-sovereiniteit voor teams, bedrijven en naties.
Het lokaal uitvoeren van grote taalmodellen biedt privacy, offline mogelijkheden en nul API-kosten.
Deze benchmark laat precies zien wat men kan verwachten van 14 populaire
LLMs op Ollama op een RTX 4080.
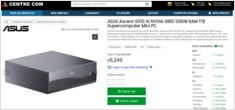
Vandaag kijken we naar de top-level consumentengrafische kaarten en RAM-modules.
Specifiek kijk ik naar
RTX-5080 en RTX-5090-prijzen, en 32GB (2x16GB) DDR5 6000.
Na automatisch installeren van een nieuw kernel, heeft Ubuntu 24.04 het ethernet-netwerk verloren. Dit vervelende probleem is voor mij opnieuw voorgekomen, dus ik documenteer de oplossing hier om anderen te helpen die hetzelfde probleem ondervinden.
Met deze gekke [prijsvolatiliteit van RAM](https://www.glukhov.org/nl/hardware/ “Analyse van GPUs, CPUs, RAM-prijzen, AI-werkstations en trends in compute-infrastructuur. Economie en prestatieoverwegingen van hardware voor moderne werklasten.) om een beter beeld te krijgen, laten we eerst zelf de RAM-prijzen in Australië volgen.
Implementeer enterprise AI op budgethardware met open modellen
De democratisering van AI is een feit.
Met open-source LLM’s zoals Llama, Mistral en Qwen die nu eigen modellen rivaliseren, kunnen teams krachtige AI-infrastructuur op consumentenhardware bouwen – kosten drastisch verlagen terwijl volledige controle over gegevensprivacy en implementatie behouden blijft.
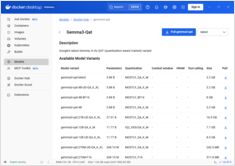
Ik vond enkele interessante prestatietests van GPT-OSS 120b die draaien op Ollama over drie verschillende platforms: NVIDIA DGX Spark, Mac Studio, en RTX 4080. De GPT-OSS 120b model uit de Ollama bibliotheek weegt 65 GB, wat betekent dat het niet past in de 16 GB VRAM van een RTX 4080 (of de nieuwere RTX 5080).
Snelle verwijzing naar Docker Model Runner-commands
Docker Model Runner (DMR) is de officiële oplossing van Docker voor het lokaal uitvoeren van AI-modellen, geïntroduceerd in april 2025. Deze cheatsheet biedt een snelle verwijzing naar alle essentiële opdrachten, configuraties en beste praktijken.