

Verlaag LLM-kosten: Tokenoptimalisatiestrategieën
Verlaag LLM-kosten met 80% door slimme tokenoptimalisatie
Tokenoptimalisatie is de kritieke vaardigheid die het verschil maakt tussen kostenefficiënte LLM-toepassingen en kostbare experimenten.
Verlaag LLM-kosten met 80% door slimme tokenoptimalisatie
Tokenoptimalisatie is de kritieke vaardigheid die het verschil maakt tussen kostenefficiënte LLM-toepassingen en kostbare experimenten.

Maak MCP-servers voor AI-assistenten met Python-voorbeelden
De Model Context Protocol (MCP) is revolutionair voor de manier waarop AI-assistenten met externe gegevensbronnen en tools interacteren. In deze gids bespreken we hoe je MCP-servers in Python kunt bouwen, met voorbeelden gericht op webzoekfuncties en web scraping.

Zichtbaar verschillende APIs vereisen een speciale aanpak.
Hier is een zij-aan-zij vergelijking van de ondersteuning voor gestructureerde uitvoer (het verkrijgen van betrouwbare JSON) bij populaire LLM-aanbieders, plus minimale Python-voorbeelden

Een paar manieren om gestructureerde uitvoer te krijgen van Ollama
Large Language Models (LLMs) zijn krachtig, maar in productie willen we zelden vrije tekst. In plaats daarvan willen we voorspelbare data: kenmerken, feiten of gestructureerde objecten die je kunt voeden in een app. Dat is LLM Structured Output.
Omschrijving, lijst met opdrachten en toetsencombinaties
Hier is een up-to-date GitHub Copilot cheat sheet, die essentiële snelkoppelingen, opdrachten, gebruikstips en contextfuncties voor Visual Studio Code en Copilot Chat behandelt
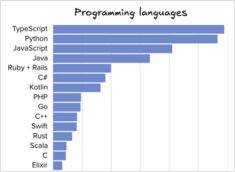
Vergelijking van software-engineering-tools en -talen
Het Pragmatic Engineer letter verscheen een paar dagen geleden met een enquête over de populariteit van programmeertalen, IDEs, AI-tools en andere gegevens voor het midden van 2025.

In juli 2025, het zou binnenkort beschikbaar moeten zijn.
Nvidia staat op het punt om de NVIDIA DGX Spark uit te brengen: een klein AI-supercomputerapparaat gebaseerd op de Blackwell-architectuur, met meer dan 128 GB unified RAM en een AI-prestatie van 1 PFLOPS. Een leuk apparaat om LLM’s op uit te voeren.

Langere lezing over MCP-specs en implementatie in GO
Hier hebben we een beschrijving van het Model Context Protocol (MCP), korte aantekeningen over hoe je een MCP-server in Go kunt implementeren, inclusief berichtstructuur en protocolespecificaties.

RAG implementeren? Hier zijn enkele codefragmenten in Go - deel 2...
Omdat standaard Ollama geen directe rerank-API heeft, moet je reranking implementeren met Qwen3 Reranker in GO door embeddings te genereren voor query-documentparen en deze te scoren.
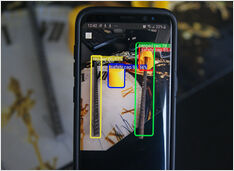
Een tijd geleden heb ik een objectdetectie AI getraind
Op een koude winterdag in juli … dat is in Australië … had ik plotseling het gevoel om een AI-model te trainen voor het detecteren van ongedekte betonversterkbalken…

RAG implementeren? Hier zijn enkele codefragmenten in Golang..
Deze kleine Reranking Go-codevoorbeeld roept Ollama aan om embeddings te genereren voor de query en voor elk kandidaatdocument, en sorteer deze vervolgens aflopend op cosijnsimilariteit.

Nieuwe, geweldige LLM's beschikbaar in Ollama
De Qwen3 Embedding en Reranker-modellen zijn de nieuwste releases in de Qwen-familie, specifiek ontworpen voor geavanceerde tekst-inbedding (embedding), ophalen (retrieval) en her-ranking taken.

Wat is deze trendy AI-ondersteunde programmeertaal?
Vibe coding is een AI-gestuurde programmeerbenadering waarbij ontwikkelaars gewenste functionaliteit beschrijven in natuurlijke taal, waardoor AI-tools automatisch code kunnen genereren.

Het volledige pakket MM*-tools is met EOL...
Ik heb MMDetection (mmengine, mdet, mmcv) vrij veel gebruikt,
en nu lijkt het erop dat het niet meer in gebruik is.
Dat is jammer. Ik vond de modelzoo leuk.

Innovatief nieuw AI-model om afbeeldingen te genereren op basis van tekst
Recentie Black Forest Labs heeft een set van tekst-naar-afbeelding AI-modellen gepubliceerd. Deze modellen worden gezegd te hebben veel hogere uitvoerkwaliteit. Laten we ze uitproberen

Een vergelijking van twee zelfgehoste AI zoekmachines
Prachtige voedsel is ook een genot voor de ogen. Maar in dit bericht vergelijken we twee AI-gebaseerde zoeksystemen, Farfalle en Perplexica.