
Modelli Qwen3 Embedding & Reranker su Ollama: Prestazioni all'avanguardia
Nuovi LLM fantastici disponibili in Ollama
I modelli Qwen3 Embedding e Reranker sono le ultime release della famiglia Qwen, specificamente progettati per compiti avanzati di embedding del testo, recupero e rirango.
Gioia per l’occhio
I modelli Qwen3 Embedding e Reranker rappresentano un significativo avanzamento nel processing del linguaggio naturale multilingue (NLP), offrendo prestazioni all’avanguardia nei compiti di embedding e rirango del testo. Questi modelli, parte della serie Qwen sviluppata da Alibaba, sono progettati per supportare una vasta gamma di applicazioni, dal recupero semantico alla ricerca di codice. Sebbene Ollama sia una popolare piattaforma open source per l’hosting e il deployment di modelli linguistici di grandi dimensioni (LLMs), l’integrazione dei modelli Qwen3 con Ollama non è specificamente dettagliata nella documentazione ufficiale. Tuttavia, i modelli sono accessibili tramite Hugging Face, GitHub e ModelScope, permettendo un potenziale deployment locale tramite Ollama o strumenti simili.
Esempi utilizzando questi modelli
Per favore vedi il codice di esempio in Go utilizzando ollama con questi modelli:
- Rirango documenti di testo con Ollama e modello Qwen3 Embedding - in Go
- Rirango documenti di testo con Ollama e modello Qwen3 Reranker - in Go
Panoramica dei nuovi modelli Qwen3 Embedding e Reranker su Ollama
Questi modelli sono ora disponibili per il deployment su Ollama in diverse dimensioni, offrendo prestazioni all’avanguardia e flessibilità per una vasta gamma di applicazioni relative al linguaggio e al codice.
Caratteristiche principali e capacità
-
Dimensioni del modello e flessibilità
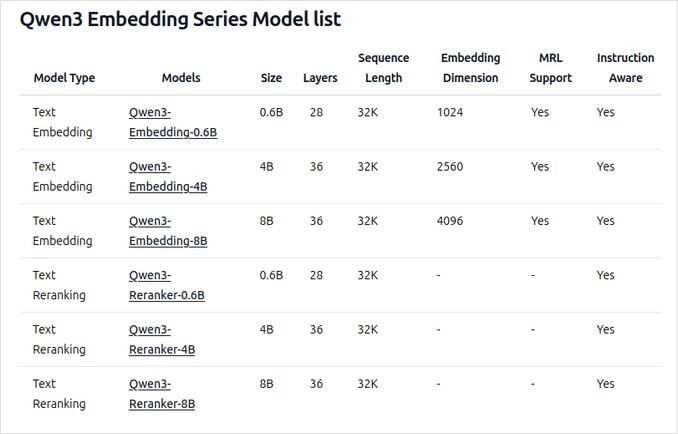
- Disponibili in diverse dimensioni: 0,6B, 4B e 8B parametri per entrambi i compiti di embedding e rirango.
- Il modello di embedding da 8B attualmente occupa la posizione numero 1 nella classifica multilingue MTEB (come di giugno 5, 2025, con un punteggio di 70,58).
- Supporta una gamma di opzioni di quantizzazione (Q4, Q5, Q8, ecc.) per bilanciare prestazioni, utilizzo della memoria e velocità. Q5_K_M è consigliato per la maggior parte degli utenti poiché preserva la maggior parte delle prestazioni del modello mentre è efficiente in termini di risorse.
-
Architettura e addestramento
- Costruiti sulla base del Qwen3, sfruttando sia l’architettura dual-encoder (per gli embedding) che l’architettura cross-encoder (per il rirango).
- Modello di embedding: Processa singoli segmenti di testo, estraiendo rappresentazioni semantiche dallo stato nascosto finale.
- Modello di rirango: Prende coppie di testo (ad esempio, query e documento) e genera un punteggio di rilevanza utilizzando un approccio cross-encoder.
- I modelli di embedding utilizzano un paradigma di addestramento a tre fasi: pre-addestramento contrastivo, addestramento supervisionato con dati di alta qualità e fusione del modello per una generalizzazione e adattabilità ottimali.
- I modelli di rirango vengono addestrati direttamente con dati etichettati di alta qualità per efficienza ed efficacia.
-
Supporto multilingue e multitask
- Supporta oltre 100 lingue, tra cui linguaggi di programmazione, abilitando capacità robuste di recupero multilingue, cross-lingue e di codice.
- I modelli di embedding permettono definizioni flessibili di vettori e istruzioni definite dagli utenti per adattare le prestazioni a compiti specifici o lingue.
-
Prestazioni e casi d’uso
- Risultati all’avanguardia nel recupero del testo, recupero del codice, classificazione, clustering e mining di bitext.
- I modelli di rirango eccellono in vari scenari di recupero del testo e possono essere combinati in modo fluido con i modelli di embedding per pipeline di recupero end-to-end.
Come utilizzarli su Ollama
Puoi eseguire questi modelli su Ollama con comandi come:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Scegli la versione di quantizzazione che meglio si adatta alle tue esigenze hardware e di prestazioni.
Tabella riassuntiva
| Tipo di modello | Dimensioni disponibili | Forza principale | Supporto multilingue | Opzioni di quantizzazione |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Punteggi MTEB di alto livello, flessibili, efficienti, SOTA | Sì (100+ lingue) | Q4, Q5, Q6, Q8, ecc. |
| Reranker | 0,6B, 4B, 8B | Eccellente nel rilevamento di coppie di testo, efficiente, flessibile | Sì | F16, Q4, Q5, ecc. |
Notizia fantastica!
I modelli Qwen3 Embedding e Reranker su Ollama rappresentano un significativo balzo in avanti nelle capacità di recupero multilingue e multitask del testo e del codice. Con opzioni di deployment flessibili, prestazioni di benchmark forti e supporto per una vasta gamma di lingue e compiti, sono adatti sia per ambienti di ricerca che per produzione.
Model zoo - piacere per l’occhio ora
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
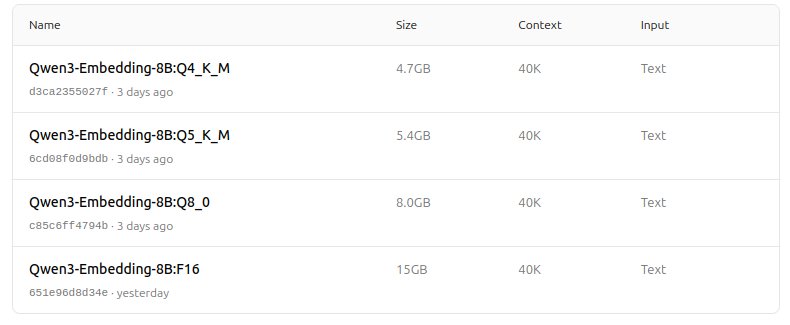
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
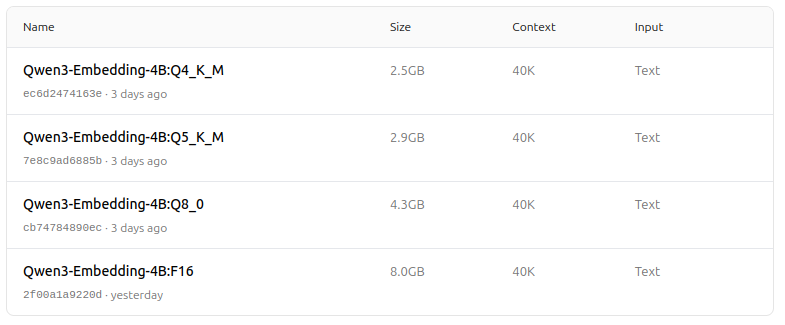
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
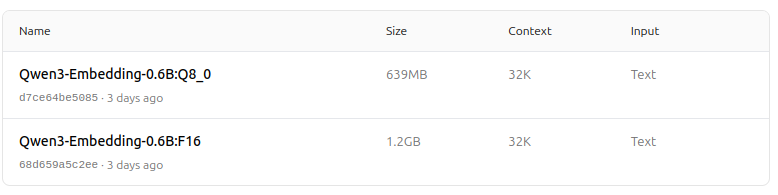
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
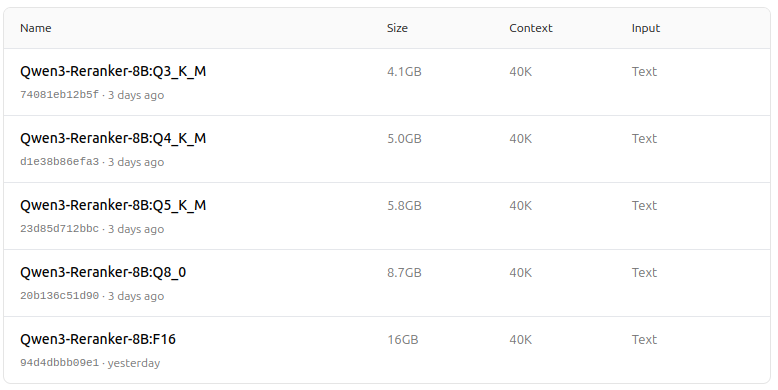
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
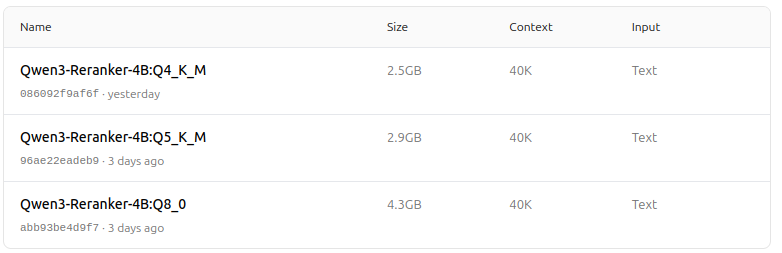
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
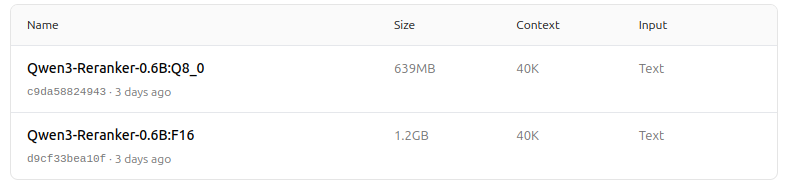
Bello!
Link utili
- Rirango documenti di testo con Ollama e modello Qwen3 Embedding - in Go
- Rirango documenti di testo con Ollama e modello Qwen3 Reranker - in Go
- Ollama cheatsheet
- Spostare i modelli Ollama su un diverso disco o cartella
- Autohosting di Perplexica - con Ollama
- Test: Come Ollama utilizza le prestazioni e i core efficienti del processore Intel
- Velocità delle prestazioni LLM
- Confronto delle capacità di sintesi LLM
- Fornitori LLM in cloud
- Come Ollama gestisce le richieste parallele
- Confronto della qualità della traduzione delle pagine Hugo - LLMs su Ollama
