
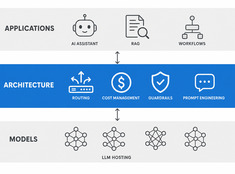
LLM-Architektur: Systemdesign für KI im Produktivbetrieb
Design decisions for production LLM systems — routing, cost, guardrails, and multi-model orchestration. The layer between running models and building reliable AI applications.
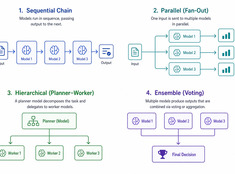
Wählen Sie das einfachste Muster, das funktioniert.
Einzige-Modell-Systeme sind einfach. Multi-Modell-Systeme sind leistungsstark. Die Herausforderung besteht nicht darin, Modelle auszuwählen, sondern die Architektur zu entwerfen, die sie orchestriert.
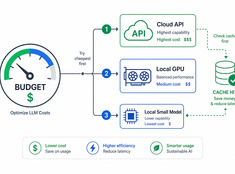
Verwende Tokens dort, wo es wirklich zählt.
Die Kosten für LLMs steigen linear mit der Nutzung. Ein System, das täglich 10.000 Anfragen mit $0,01 pro Anfrage verarbeitet, kostet täglich $100 — also $365 pro Jahr. Im Unternehmensmaßstab belaufen sich die Kosten auf über $10.000.
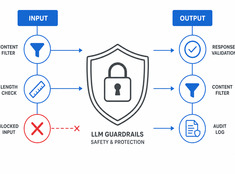
Steuern Sie das Risiko, nicht nur das Modell.
LLMs sind unvorhersehbar. Sie halluzinieren, geben Daten preis, generieren schädliche Inhalte oder lehnen legitime Anfragen ab. Guardrails (Sicherheitsvorkehrungen) beschränken das Modellverhalten, ohne dabei die Fähigkeiten zu beeinträchtigen.
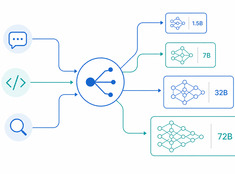
Das richtige Modell für die richtige Aufgabe.
Das Ausführen eines Modells mit 70 Milliarden Parametern, um eine 200-Wörter-E-Mail zusammenzufassen, ist verschwenderisch. Das Ausführen eines 3-Milliarden-Parameter-Modells zur Überprüfung von Produktionscode ist fahrlässig. Die meisten Systeme liegen irgendwo dazwischen – und genau hier kommt das Modell-Routing ins Spiel.

Arbeits-, Struktur- und Abrufgedächtnis für Assistenten.
Speicher verwandelt Assistenten von reaktiv in persistent, ist aber auch der Ort, an dem viele Systeme stillschweigend veralten. Umfragen argumentieren, dass die Trennung zwischen kurzfristigem und langfristigem Speicher für moderne Agenten-Speicher nicht mehr ausreicht; OpenAI- und LangGraph-SDKs weisen auf einen einfacheren Stack hin – Arbeitsgedächtnis, dauerhafter Zustand und Abruf.

Wie ernsthafte Assistenten tatsächlich aufgebaut sind.
Ein AI-Assistent für den produktiven Einsatz ist nicht einfach „ein LLM mit einem Prompt“. Er ist ein System, das Absichten akzeptiert, Zustand verwaltet, entscheidet, wann abgerufen oder gehandelt werden soll, und genügend Runtime-Details offenlegt, um Fehler zu analysieren.

KI verändert das Wissensmanagement, nicht seinen Zweck.
KI ersetzt nicht das Wissensmanagement; sie verändert dessen Gestalt für Einzelpersonen und Teams gleichermaßen.
Stars, Tokens, Downloads – wer gewinnt tatsächlich?
Open-Source-KI-Agent-Frameworks erfreuen sich auf GitHub einer explosionsartigen Popularität. Zwei Projekte im Herzen des Ökosystems der selbst gehosteten KI-Systeme — OpenClaw und Hermes Agent — haben sich so stark abgesetzt, dass der Rest des Feldes um einen entfernten dritten Platz kämpft.

MTP im Vergleich zur Standard-Decodierung auf der RTX 4080 – echte Benchmarks
Ich habe die Leistung von spekulativem Decoding (Multi-Token Prediction, MTP) bei Qwen 3.6 27B und 35B auf einer RTX 4080 mit 16 GB VRAM getestet.

Kostenfreier VRAM, ohne den llama-server zu beenden.
llama.cpp Router-Modus ist eine der nützlichsten Änderungen an llama-server in den letzten Jahren. Er gibt lokalen LLM-Betreibern endlich etwas, das dem Modellmanagement-Erlebnis ähnelt, das man von Ollama erwartet, während er die rohe Leistung und die niedrige Kontrollstufe beibehält, die llama.cpp überhaupt erst interessant machen.

Kompiliertes Wissen für KI-Systeme
Die Prämisse ist einfach: Kompiliertes Wissen ist wiederverwertbarer als abgerufene Fragmente. RAG wurde zur Standardantwort auf eine einfache Frage – wie gewähre ich einem LLM Zugriff auf externes Wissen?

Eine Landkarte moderner Wissenssysteme
PKM, RAG, Wikis, KI-Speichersysteme und nun praktische, KI-gestützte Workflows werden oft so diskutiert, als lösten sie dasselbe Problem. Das tun sie nicht. Sie alle befassen sich mit Wissen, arbeiten aber auf unterschiedlichen Ebenen:

Hören Sie auf, auf Vibes zu vertrauen. Validieren Sie Verträge.
Die meisten Tutorials zu „strukturierten Ausgaben“ von LLMs sind wenig ernst gemeint. Sie lehren Sie, höflich um JSON zu bitten und darauf zu hoffen, dass das Modell sich entsprechend verhält. Das ist keine Validierung. Das ist Optimismus mit geschweiften Klammern.

Referenz für die Feinabstimmung von agentic LLMs
Diese Seite dient als praktische Referenz für die Optimierung der agentischen LLM-Inferenz (Temperatur, top_p, top_k, Penalties und deren Interaktion in mehrstufigen und tool-lastigen Workflows).

Sprechen Sie mit Hermes von Ihrem Telefon
Sie chatten bereits mit dem Hermes-Agenten auf Ihrem Smartphone über Text. Jetzt möchten Sie direkt mit ihm sprechen und gesprochene Antworten erhalten. Das ist in der Regel der richtige Schritt, insbesondere wenn Sie Hermes bereits als persistenten, selbst gehosteten Assistenten nutzen. Lange Prompts auf einem kleinen Bildschirm einzutippen ist langsam und fehleranfällig.