
Qwen3 Embedding- en Rerankmodellen op Ollama: State-of-the-Art-prestaties
Nieuwe geweldige LLMs beschikbaar in Ollama
De Qwen3 Embedding en Reranker modellen zijn de nieuwste uitgaven in de Qwen-familie, specifiek ontworpen voor geavanceerde tekst-embedding, ophalen en herordenen taken.
Vreugde voor het oog
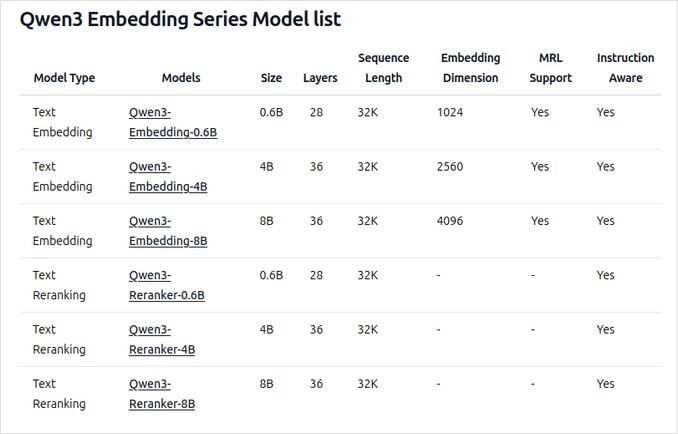
De Qwen3 Embedding en Reranker modellen stellen een aanzienlijke vooruitgang voor in het multitaalige natuurlijke taalverwerking (NLP), met state-of-the-art prestaties in tekst-embedding en herordenen taken. Deze modellen, onderdeel van de Qwen-reeks ontwikkeld door Alibaba, zijn ontworpen om een breed scala aan toepassingen te ondersteunen, van semantische ophaling tot codezoekopdrachten. Hoewel Ollama een populaire open-source platform is voor het hosten en implementeren van grote taalmodellen (LLMs), is de integratie van Qwen3 modellen met Ollama niet expliciet beschreven in officiële documentatie. De modellen zijn echter beschikbaar via Hugging Face, GitHub en ModelScope, waardoor lokale implementatie mogelijk is via Ollama of vergelijkbare tools.
Voorbeelden van het gebruik van deze modellen
Zie het voorbeeldcode in Go met ollama en deze modellen:
- Herordenen van tekstdocumenten met Ollama en Qwen3 Embedding model - in Go
- Herordenen van tekstdocumenten met Ollama en Qwen3 Reranker model - in Go
Overzicht van nieuwe Qwen3 Embedding en Reranker modellen op Ollama
Deze modellen zijn nu beschikbaar voor implementatie op Ollama in verschillende groottes, met state-of-the-art prestaties en flexibiliteit voor een breed scala aan taal- en codegerelateerde toepassingen.
Belangrijke kenmerken en mogelijkheden
-
Modelgroottes en flexibiliteit
- Beschikbaar in meerdere groottes: 0,6B, 4B en 8B parameters voor zowel embedding als herordenen taken.
- Het 8B embedding model staat momenteel op de eerste plaats op de MTEB multitaalleaderboard (zoals van 5 juni 2025, met een score van 70,58).
- Ondersteunt een breed scala aan kwantisatieopties (Q4, Q5, Q8, enz.) voor het balanceren van prestaties, geheugengebruik en snelheid. Q5_K_M wordt aanbevolen voor de meeste gebruikers, omdat het de meeste modelprestaties behoudt terwijl het resource-efficiënt is.
-
Architectuur en training
- Opgebouwd op de Qwen3 basis, met gebruikmaking van zowel dual-encoder (voor embeddings) als cross-encoder (voor herordenen) architectuur.
- Embedding model: Verwerkt enkele tekstsegmenten en haalt semantische representaties op uit de eindverborgen toestand.
- Herordenenmodel: Neemt tekstparen (bijvoorbeeld query en document) en geeft een relevantiescore uit met een cross-encoder aanpak.
- Embeddingmodellen gebruiken een driedaagse trainingparadigma: contrastieve voortraining, gesuperviseerde training met hoogwaardige data en modelvereniging voor optimale generalisatie en aanpasbaarheid.
- Herordenenmodellen worden direct getraind met hoogwaardige gelabelde data voor efficiëntie en effectiviteit.
-
Multitaal- en multitaskondersteuning
- Ondersteunt meer dan 100 talen, waaronder programmeertalen, waardoor robuuste multitaal, cross-linguaal en codezoekfunctionaliteiten mogelijk zijn.
- Embeddingmodellen toestaan flexibele vectordefinities en gebruikersgedefinieerde instructies om prestaties aan te passen aan specifieke taken of talen.
-
Prestaties en gebruiksscenario’s
- State-of-the-art resultaten in tekstophaling, codeophaling, classificatie, clustering en bitext-mining.
- Herordenenmodellen excelleren in verschillende tekstophalingsscenario’s en kunnen eenvoudig worden gecombineerd met embeddingmodellen voor eind-naar-eind ophalingspijplijnen.
Hoe gebruik je het op Ollama
Je kunt deze modellen op Ollama uitvoeren met opdrachten zoals:
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Kies de kwantisatieversie die het beste past bij je hardware en prestatiebehoeften.
Samenvattingstabel
| Modeltype | Beschikbare groottes | Belangrijkste sterktes | Multitaalondersteuning | Kwantisatieopties |
|---|---|---|---|---|
| Embedding | 0,6B, 4B, 8B | Top MTEB scores, flexibel, efficiënt, SOTA | Ja (100+ talen) | Q4, Q5, Q6, Q8, enz. |
| Herordenen | 0,6B, 4B, 8B | Excelleert in relevantie van tekstparen, efficiënt, flexibel | Ja | F16, Q4, Q5, enz. |
Geweldige nieuws!
De Qwen3 Embedding en Reranker modellen op Ollama stellen een aanzienlijke sprong voorwaarts in multitaalige, multitask tekst- en codeophalingsfunctionaliteiten. Met flexibele implementatieopties, sterke benchmarkprestaties en ondersteuning voor een breed scala aan talen en taken, zijn ze goed geschikt voor zowel onderzoeks- als productieomgevingen.
Modelzoo - vreugde voor het oog nu
Qwen3 Embedding
https://ollama.com/dengcao/Qwen3-Embedding-8B
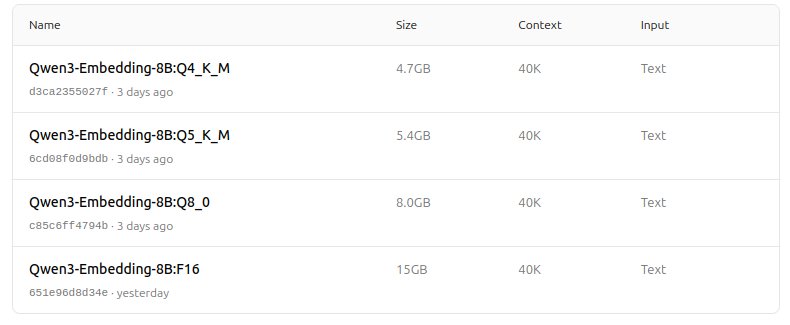
https://ollama.com/dengcao/Qwen3-Embedding-4B/tags
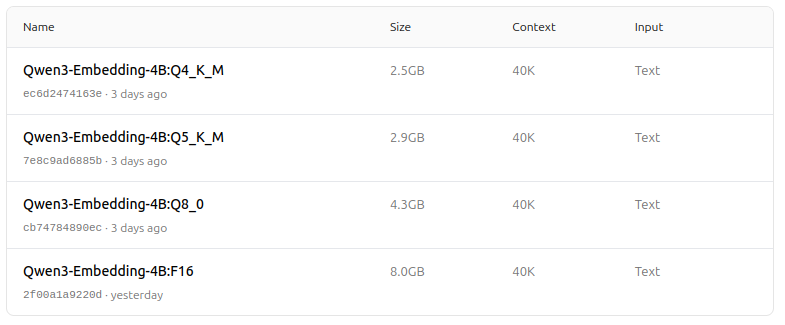
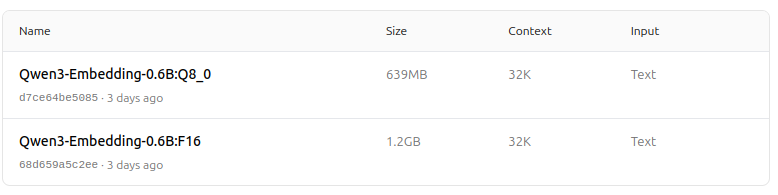
https://ollama.com/dengcao/Qwen3-Embedding-0.6B/tags
Qwen3 Reranker
https://ollama.com/dengcao/Qwen3-Reranker-8B
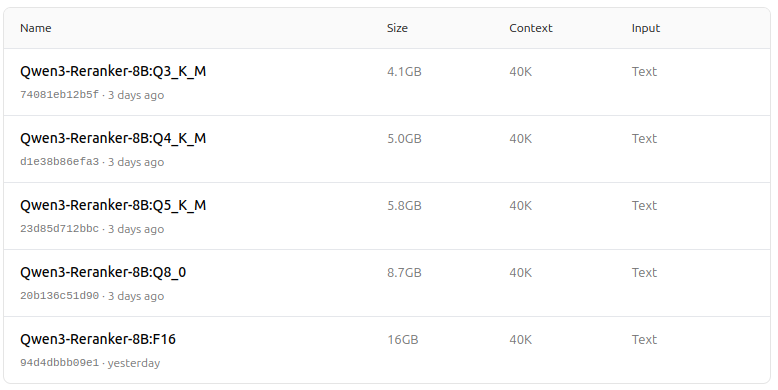 dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
dengcao/Qwen3-Reranker-8B:Q3_K_M
dengcao/Qwen3-Reranker-8B:Q5_K_M
https://ollama.com/dengcao/Qwen3-Reranker-4B/tags
dengcao/Qwen3-Reranker-4B:Q5_K_M
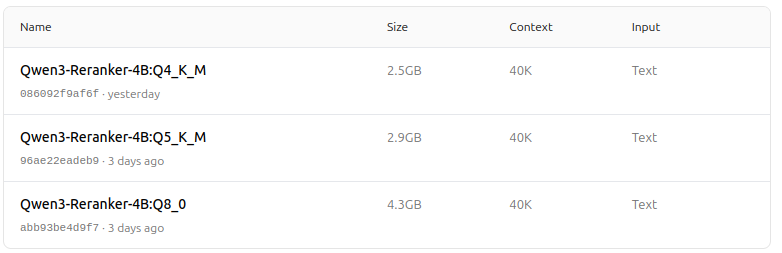
https://ollama.com/dengcao/Qwen3-Reranker-0.6B/tags
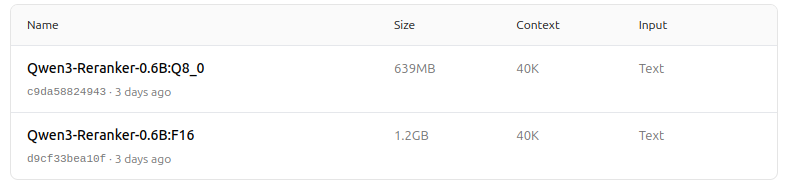
Leuk!
Nuttige links
- Herordenen van tekstdocumenten met Ollama en Qwen3 Embedding model - in Go
- Herordenen van tekstdocumenten met Ollama en Qwen3 Reranker model - in Go
- Ollama cheatsheet
- Verplaats Ollama modellen naar een andere schijf of map
- Self-hosting Perplexica - met Ollama
- Test: Hoe Ollama Intel CPU-prestaties en efficiënte kernen gebruikt
- LLM snelheidsprestatiesvergelijking
- Vergelijking van LLM samenvattingsvermogen
- Cloud LLM leveranciers
- Hoe Ollama parallelle aanvragen behandelt
- Vergelijking van Hugo Pagina vertaalkwaliteit - LLMs op Ollama
